A Serverless Query Engine from Spare Parts


Previously published in Towards Data Science on 04/26/2023.

In this post we will show how to build a simple end-to-end application in the cloud on a serverless infrastructure. The purpose is simple: we want to show that we can develop directly against the cloud while minimizing the cognitive overhead of designing and building infrastructure. Plus, we will put together a design that minimizes costs compared to modern data warehouses, such as Big Query or Snowflake.
As data practitioners we want (and love) to build applications on top of our data as seamlessly as possible. Whether you work in BI, Data Science or ML all that matters is the final application and how fast you can see it working end-to-end. The infrastructure often gets in the way though.
Imagine, as a practical example, that we need to build a new customer-facing analytics application for our product team. Because it’s client-facing we have performance constraints we need to respect, such as low latency.
We can start developing it directly in the cloud, but it would immediately bring us to some infra questions: where do we run it? How big a machine do we need? Because of the low-latency requirement, do we need to build a caching layer? If so, how do we do it?
Alternatively, we can develop our app locally. It will probably be more intuitive from the developer experience point of view but it only postpones the infra questions, since in the end we will have to find a way to go from our local project to actual pipelines. Moreover, the data will need to leave the cloud env to go on our machine, which is not exactly secure and auditable.
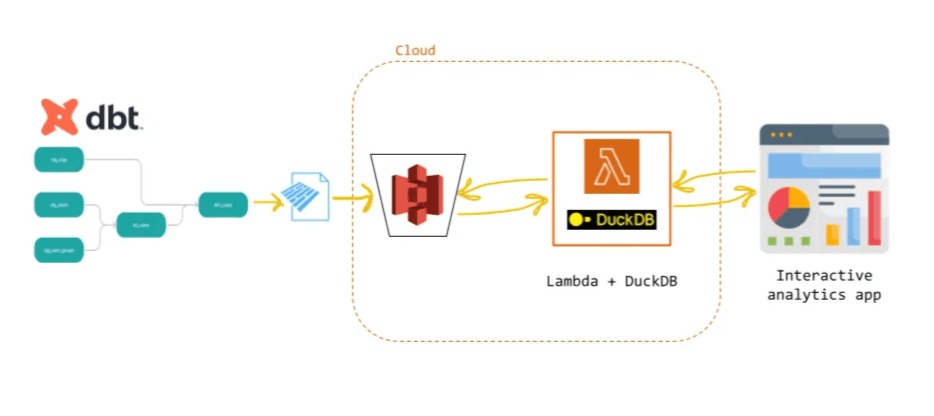
To make the cloud experience as smooth as possible we designed a data lake architecture where data are sitting in a simple cloud storage (AWS S3) and a serverless infrastructure that embeds DuckDB works as a query engine. At the end of the cycle, we will have an analytics app that can be used to both visualize and query the data in real time with virtually no infra costs.
Of course, this is a bit of a simplification, as some tweaks would be needed to run this project in real production scenarios. What we provide is a general blueprint to leverage the separation of storage and compute to build a data lake with a query engine in the cloud. We show how to power an interactive data app with an (almost) free cloud endpoint, no warehouse setup, and lighting fast performance. In our implementation, the final application is a simple Streamlit app, but that’s merely for explanatory purposes: you can easily think of plugging in your favorite BI tool.
Ducks go serverless
Y’all know DuckDB at this point. It is an open-source in-process SQL OLAP database built specifically for analytical queries. It is somewhat still unclear how much DuckDB is actually used in production , but for us today the killer feature is the possibility of querying parquet files directly in S3 with SQL syntax.
So most practitioners seem to be using it right now as a local engine for data exploration, ad hoc analysis, POCs and prototyping (with some creative ideas on how to extend its initial purpose to cover more surface). People create notebooks or small data apps with embedded DuckDB to prototype and experiment with production data locally.
The cloud is better. And if we often feel it isn’t, it’s because something is wrong with the tool chain we use, but there is a very big difference between a bad idea and a good idea badly executed .
If we combine a data lake architecture, a serverless design, DuckDB and a bit of ingenuity we can build a very fast data stack from spare parts: no warehouse setup, lighting fast performance and outrageously cheap costs — S3 most expensive standard pricing is $0.023 per GB, AWS Lambda is very fast and scales to zero when not in use, so it is a no-fat computation bill, plus AWS gives you 1M calls for free.
Buckle up, clone the repo , sing along and for more details, please refer to the README .
Architecture
This project is pretty self-contained and requires only introductory-level familiarity with cloud services and Python.
The idea is to start from a Data Lake where our data are stored. Once the data is uploaded in our S3 in a parquet format, we can then trigger the lambda with a SQL query. At that point, our lambda goes up, spins up a DuckDB instance in memory, computes the query and gets back to the user with the results, which can be directly rendered as tables in the Terminal.
The architecture has a number of advantages mostly coming from the serverless design: speed, proximity to the data and one line deployment are nice; plus, of course, the system scales to zero when not used, so we only pay per query.
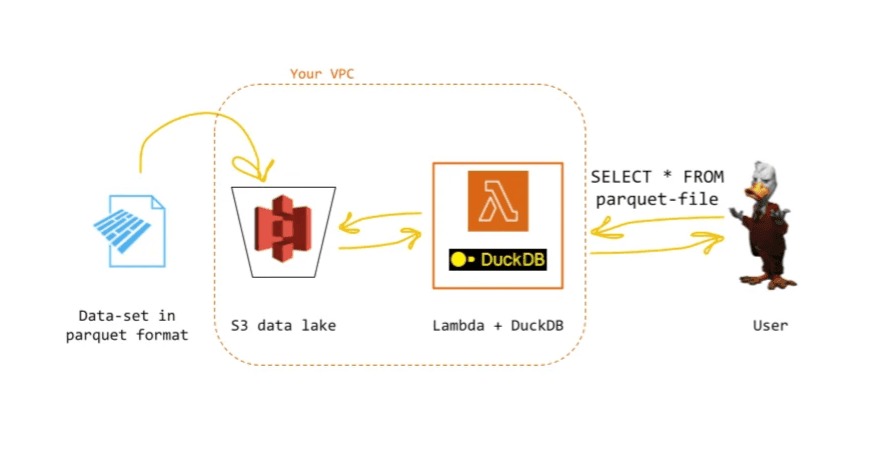
Your first query engine + data lake from spare parts
We provide a simple script that will create an S3 bucket and populate it with a portion of the NYC TLC Trip Record Data (available under the nyc.gov terms of use ), both as a unique file and as a hive-partitioned directory (you can run it with Make ). Once the data are in the data lake we can set up and use our lambda: if you have the Serverless CLI setup correctly, deploying the lambda is one command of Make again .
The lambda can be invoked in any of the usual ways, and accepts a query as its main payload: when it runs, it uses DuckDB (re-using an instance if on a warm start) to execute the query on the data lake. DuckDb does not know anything about the data before and after the execution, making the lambda purely stateless as far as data semantics is concerned.
For instance, you can use the simple Python script in the project to send this query to the lambda, and display the results:
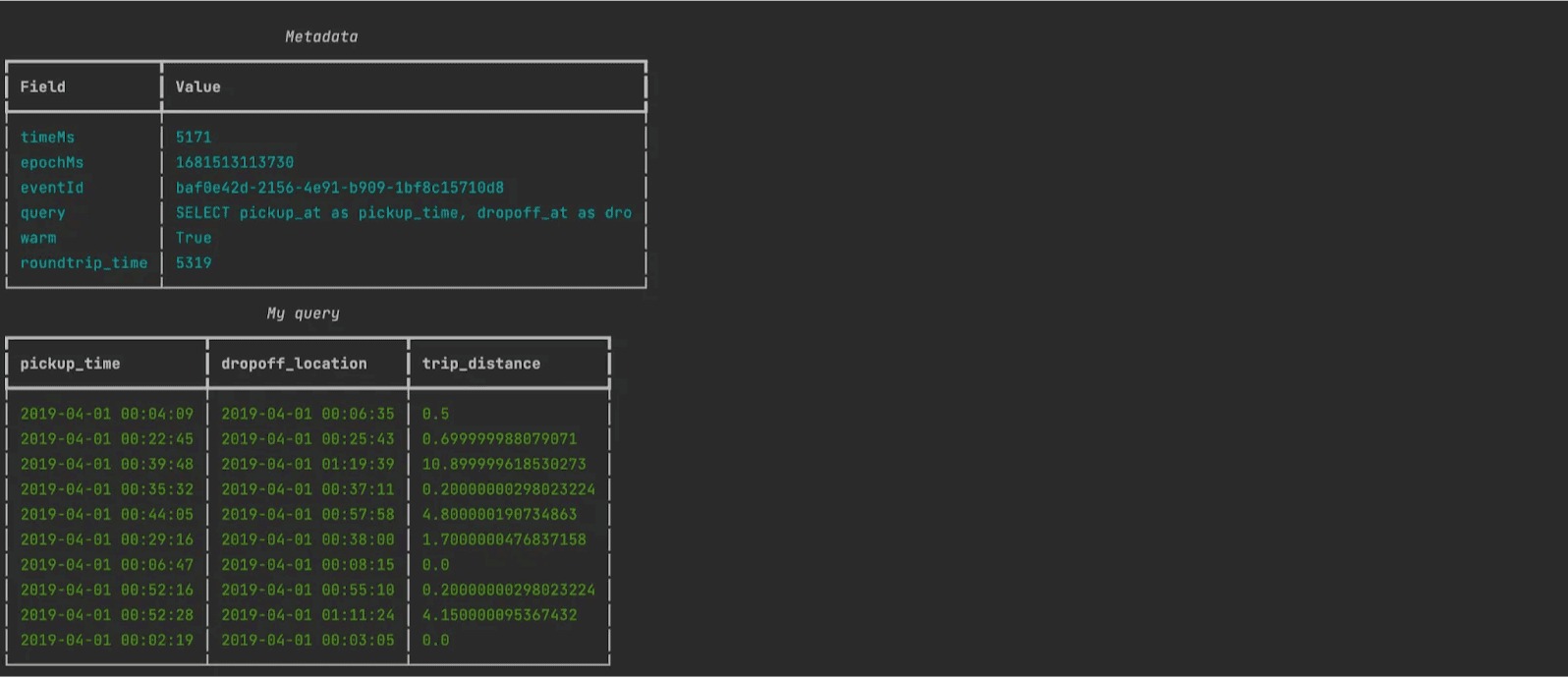
Et voilà! You can now query your data lake, securely in the cloud. This very simple design addresses directly two of the typical frictions for working in cloud data warehouses:
The setup is significantly simplified since all the user needs to do is to have her AWS credential. Once the setup is done, the user only needs access to the lambda (or any proxy to it!): that is good, as it gives the user full query capabilities without access to the underlying storage.
The performances are so good that it feels like developing locally, even if we always go through the cloud. A snappy cloud experience helps tame the too familiar feeling that advantages of working on remote machines is paid in the coin of good developer experience.
(Almost) Free Analytics
It’s all good and boujee, but let us say that we want to do a bit more than query data on the fly. Let’s say that we want to build an application on top of a table. It’s a very simple app, there is no orchestration and no need to calibrate the workload.
At the same time, let’s say that this application needs to be responsive, it needs to be fast. Anyone who deals with clients directly, for instance, knows how it is important to provide a fresh responsive experience to the clients who want to see their data. The one thing nobody likes is a dashboard that takes minutes to load.
To see how this architecture can bridge the gap between data pipelines and real-time querying for analytics, we provide a small dbt DAG to simulate running some offline SQL transformations over the original dataset resulting in a new artifact in the data lake (the equivalent of a dashboard view).
To keep things as self contained as possible, we included a version that you can run locally on your machine (see README for more details — nor dbt nor the engine behind it matter for this pattern to work). However, you can use a different runtime for dbt and export the final artifact as a parquet file, with Snowflake or BigQuery.
For the time being, we’ll stick to our super simple DAG made of two nodes. The first node takes the pickup_location_id from our data lake and order them by the number of trips:
The second that gives as the top 200 pick up locations in our data set:
We can visualize the DAG with dbt docs:
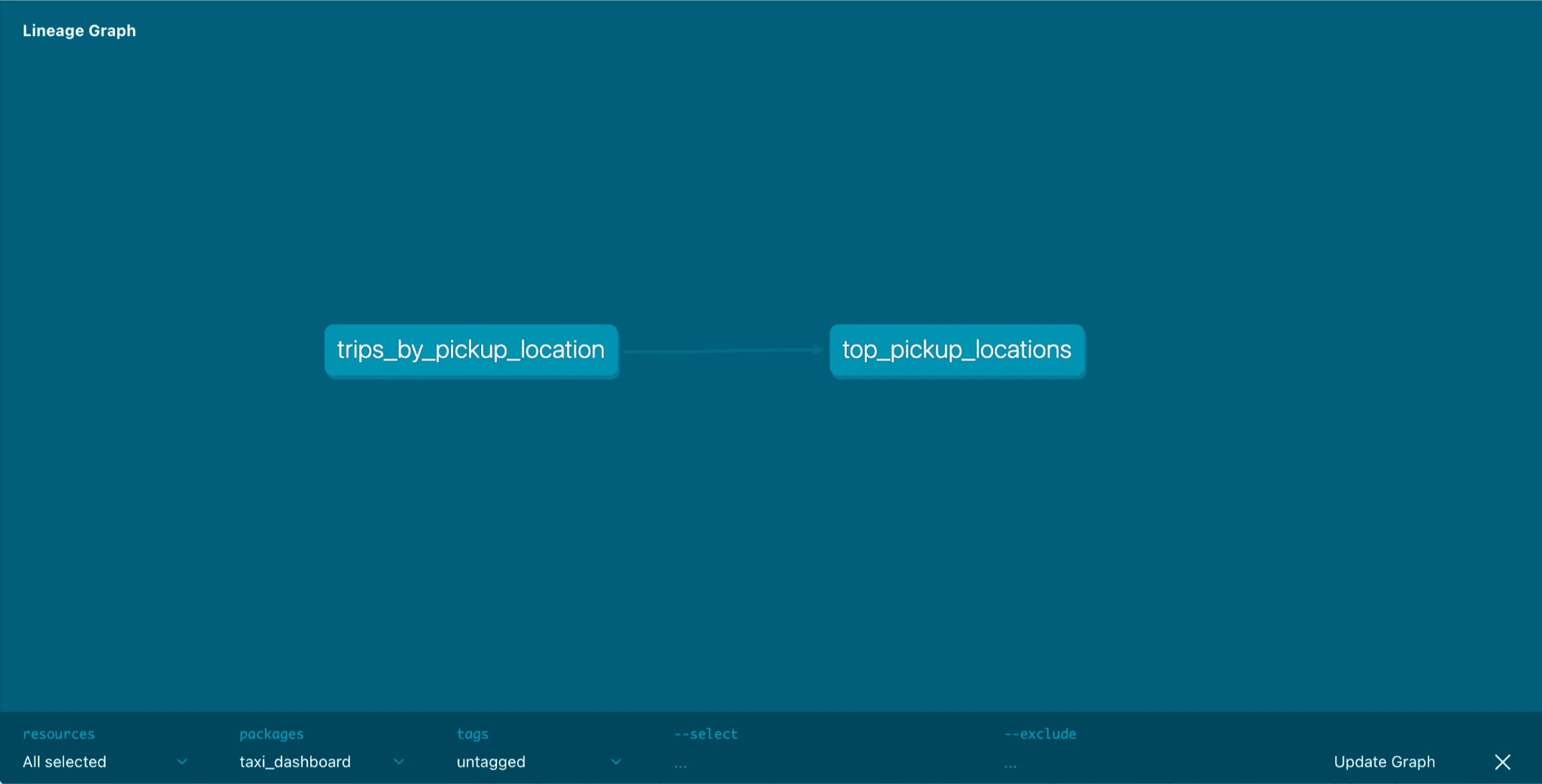
Once our pipeline is done, the final artifact is uploaded back to our data lake in:
s3:/your_s3_bucket/dashboard/my_view.parquetWe can then reuse the query engine we built before to query the second (and final) node of our DAG to visualize the data in a Streamlit app, simply by running in the terminal:
(venv) cirogreco@Ciros-MBP src % make dashboardEvery time we hit the dashboard, the dashboard hits the lambda behind the scenes. If you like this simple architecture, the same pattern can be used in your own Streamlit app, or in your favorite BI tool.
A few remarks on the “Reasonable Scale”
A while ago , we wrote a series of posts on what we called MLOps at Reasonable Scale where we talked about the best strategies to build reliable ML applications in companies that do not process data at internet scale and have a number of constraints that truly Big-Data companies typically do not have. We mostly talked about it from the point of view of ML and MLOps because operationalizing successfully ML was a major problem for organizations at the time (maybe it still is, I am not sure), but one general observation remains: most data organizations are “Reasonable Scale” and they should design their systems around this assumption. Note that being a reasonable scale organization does not necessarily mean being a small company. The enterprise world is full of data teams who deal with a lot of complexity within large — sometimes enormous — organizations and yet have many reasonable scale pipelines, often for internal stakeholders, ranging from a few GB to at most a TB.
Recently, we happily witnessed a growing debate around whether companies need Big Data systems to deal with their data problems,. The most important takeaway from our point of view remains that, if you are a Reasonable Scale organization, dealing with unnecessary infrastructure can be a very serious burden with plenty of nefarious ramifications in your organization processes. You could in principle build an entire data stack to support low latency dashboards — maybe you could use a Data Warehouse and a caching layer -, but since your resources are limited, wouldn’t it be nice to have a simpler and cheaper way?
In this post, we showed that the combination of data-first storage formats, on-demand compute and in-memory OLAP processing opens up for new possibilities at Reasonable Scale. The system is far from perfect and could use many improvements, but it shows that one can build an interactive data app with no warehouse setup, lighting fast performances and virtually no costs. By removing the db from DuckDB, we can combine what is fundamentally right about local (“single node processing is all you need”) with what is fundamentally right about the cloud (“data is better processed elsewhere”).




