Blending DuckDB and Iceberg for Optimal Cloud OLAP


Intro
Here at Bauplan, we build a fast, serverless, easy to use data lakehouse - we're on a mission to make working with huge datasets in the cloud as easy as import your_data; do_cool_stuff(your_data). Our serverless platform takes care of all the nasty infra bits, so developers can focus on building interesting stuff with data, rather than Kubernetes or Spark.
At the heart of our platform, we turn your files (e.g. Parquet, CSV) into Apache Iceberg tables automatically and expose them in simple way.
Iceberg brings sanity to data lakes with things like schema evolution, ACID transactions, and time travel, which in turn provides the ability to create lightweight data branches, so you can test out changes or experiment with production data without fear. The combination of the two it's like git for data.
To make the query side buttery smooth, we've integrated DuckDB as our execution engine. If you're not familiar with it, DuckDB is an embedded database that's been taking the data world by storm. Coined the "SQLite for analytics", it lets you run OLAP queries easily on your local files, no setup required. Pretty slick.
As engineers, we love these tools and the "do one thing well" ethos behind them. But using them together revealed some challenges. How do you preserve the user experience of DuckDB while scaling it to data lake proportions? And how do you ensure consistency with all of Iceberg's features?
The Problem
In our case, the answer is to artfully decompose these systems and rebuild them to accentuate their best qualities. But before I jump into the technical details of how we did that, let me back up and paint the problem space a bit more.
If you've worked with data lakes before, you know they can be a bit of a mess. Data goes in, but making sense of it after the fact is a nightmare. Files get partitioned in weird ways, schemas drift over time, and querying it gets as slow as molasses.
And you can point DuckDB at S3 directly. So in theory, pointing DuckDB at an Iceberg table should give us the best of both worlds, right? A consistent table layer for governance, with a sprinkle of SQL magic on top.
Well...not exactly. DuckDB does an incredible job with some analytical queries and filter pushdowns when querying against object storage, but there's some impedance mismatch using it with a catalog.
DuckDB generally expects to work on local data. It has no concept of a remote metastore or catalog. And because data lakes have so many files, often in complex partition layouts, DuckDB's native file globbing doesn't cut it.
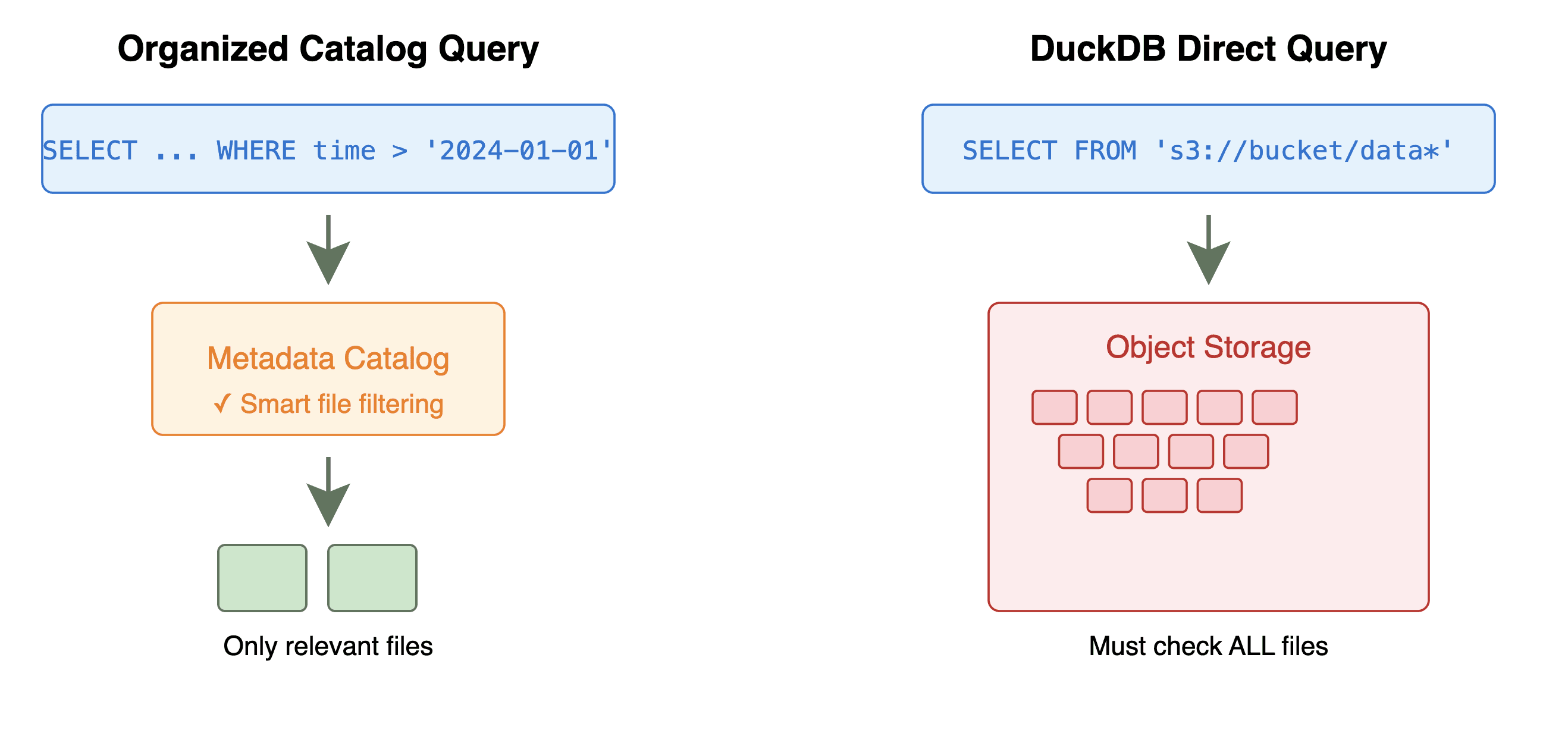
DuckDB also isn’t really well equipped to publish results back upstream to the data lake/catalog, or cache intermediate scans and results. For two similar queries, you might end up doing the same work twice. For instance:
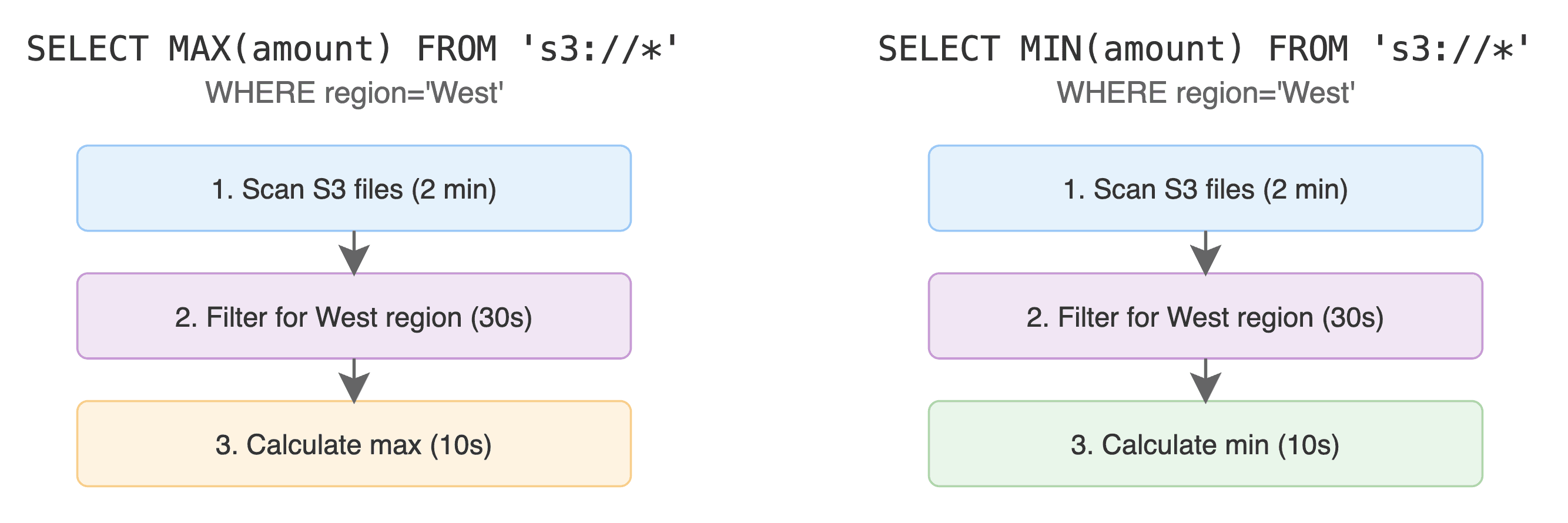
instead of:

Lastly, DuckDB operates in single-user mode. Every query gets its own fresh version of the data. That doesn't jive with the transactional guarantees and time travel features we want.
So what's a data engineer to do? Ultimately, we settled on a design that reuses DuckDB's query planning and execution, but with a custom Iceberg scan operator. Let's dig in.
The Best Laid Plans
When a user fires off a SQL query or a full pipeline run (which may have both SQL and Python steps), we first, before any data is actually loaded, ask DuckDB a hypothetical question - if we have table(s) with ABC columns and query X, what do you intend to do?
Our whole planning process requires to figure out what things we should get from the data catalog directly (i.e., do a scan) and what we will get from intermediate computation (which, in our case, can be a full pipeline run, with both Python functions and SQL queries producing intermediate dataframes).
To help us answer this question in the abstract, we decided to have a custom DuckDB fork that supports similar operations to EXPLAIN ANALYZE which exposes the query plan, run-time performance numbers and cardinality estimates. In this way, we can decompose a sophisticated query with a lot of CTEs, predicates, sub-selects and so on, and plug this information into our broader planning process. The DuckDB planner tells us which tables are being scanned, what the query predicates are, which columns are needed, and so on. Basically everything we need to figure out which data to fetch.
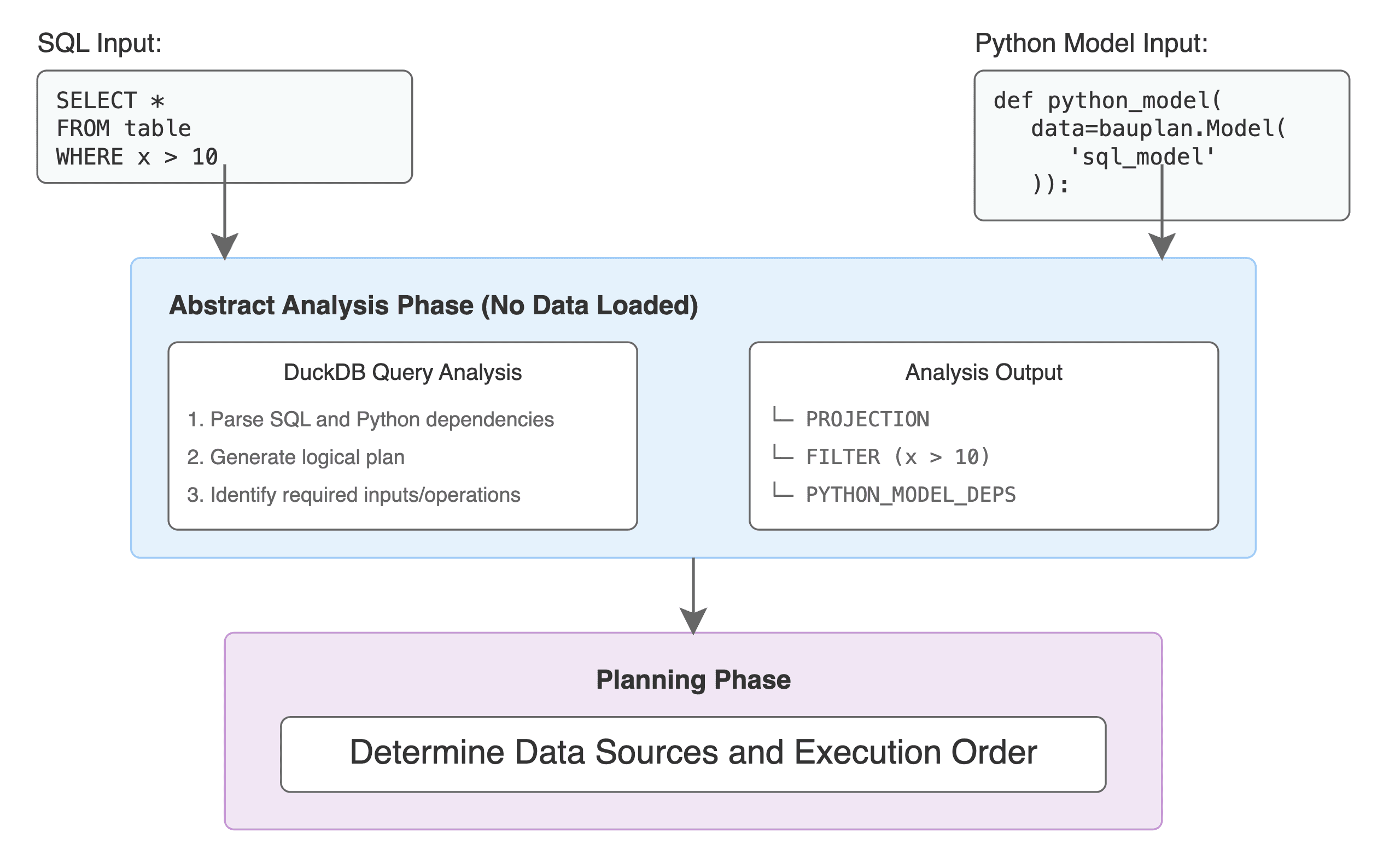
We then take this plan and rewrite the table scans to go through Iceberg instead. This is where the magic happens. Using Iceberg's catalog and manifest files, we prune down the list of files to only those that match the query predicates, enabling us to filter based on comparisons, null/not null, etc. If you're filtering on a partitioned column like date, we can skip huge swaths of the table entirely and see massive performance gains.
This step also reconciles schemas and resolves any necessary snapshots. So if you're querying a point-in-time view of the data, we make sure to only fetch files that belong to that snapshot. No consistency issues.
Then when we run the pipeline live, we scan to an Arrow table and hand it off to DuckDB directly, without any burdensome copying of the data. From DuckDB's perspective, it's like the data just appears out of thin air. It has no idea that Iceberg is even involved. Spiritually, it’s akin to this small example we can imagine for querying Github repo data:
This is great but, we're not done yet. We can continue to improve the situation in yet two more ways, caching intermediate results, and optionally materializing them.
The Hardest Problems in Computer Science
Because of how our platform is structured, we can add one more trick.
One of the main advantages of our platform is that it provides a fast feedback loop over data workloads directly in the cloud. So, after a scan, or after DuckDB is finished churning away on the provided data, we can stash those computed results in a shared cache to be used by future runs, or downstream models in the same pipeline run. Subsequent queries can then skip the Iceberg scan or DuckDB query entirely and go straight to the good stuff.
In order to manage this layer, we use the query predicate(s) themselves, as well as other properties, etc., to construct cache keys. This allows us to re-use steps across runs and have a “docker build like cache” for data. If a step upstream in the pipeline gets invalidated or changed, we can re-compute from there.
In action, you can see this in the summary table for our pipelines. First run:
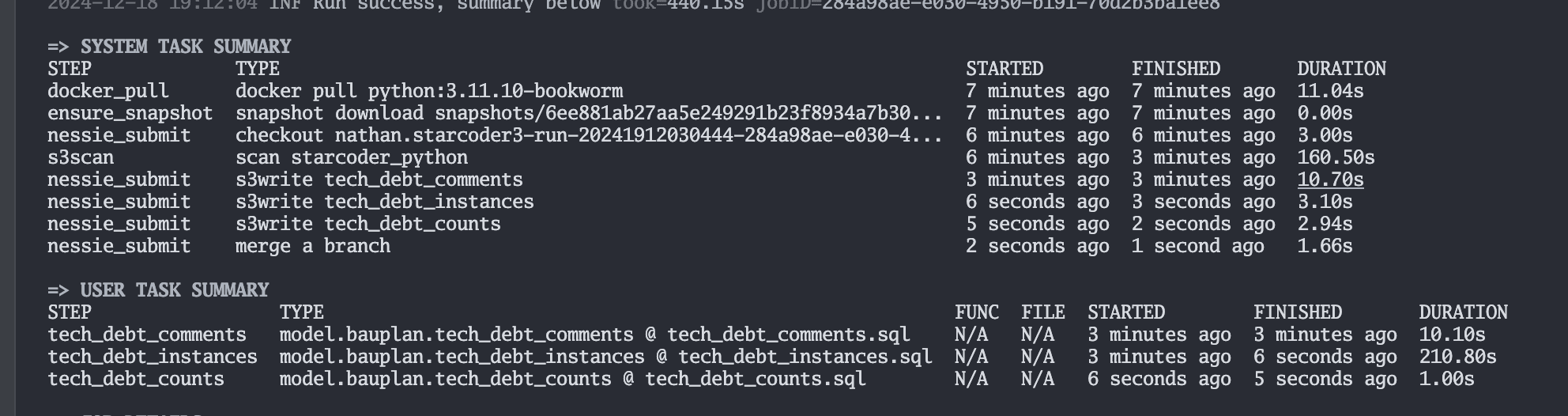
Next run, without changing anything:
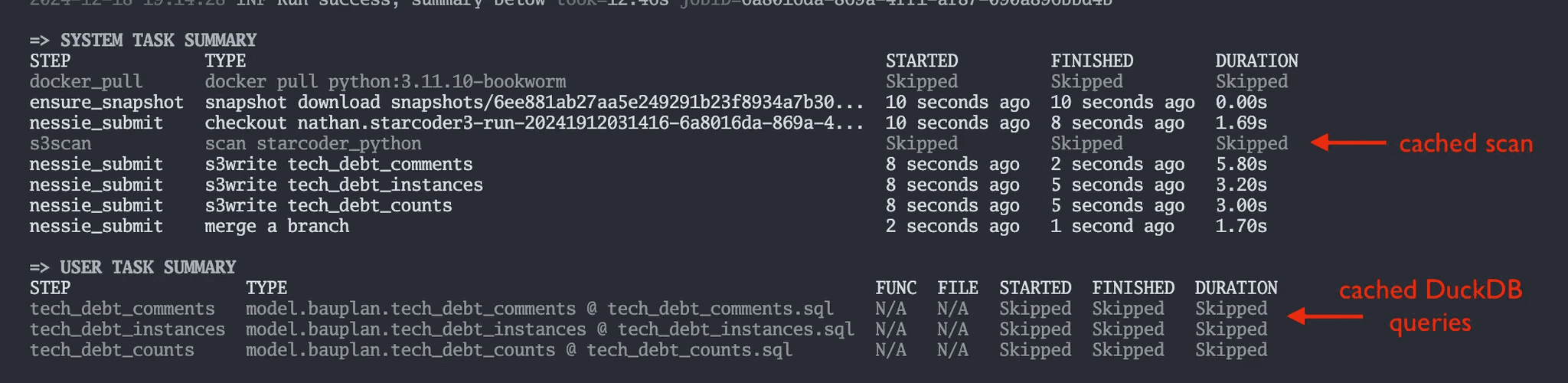
You can see that this is capable of saving us quite a lot of time across iterations, such as taking a 2+ minute data scan down to effectively a free operation on the next run. At large scale, this is becomes an insane performance gain.
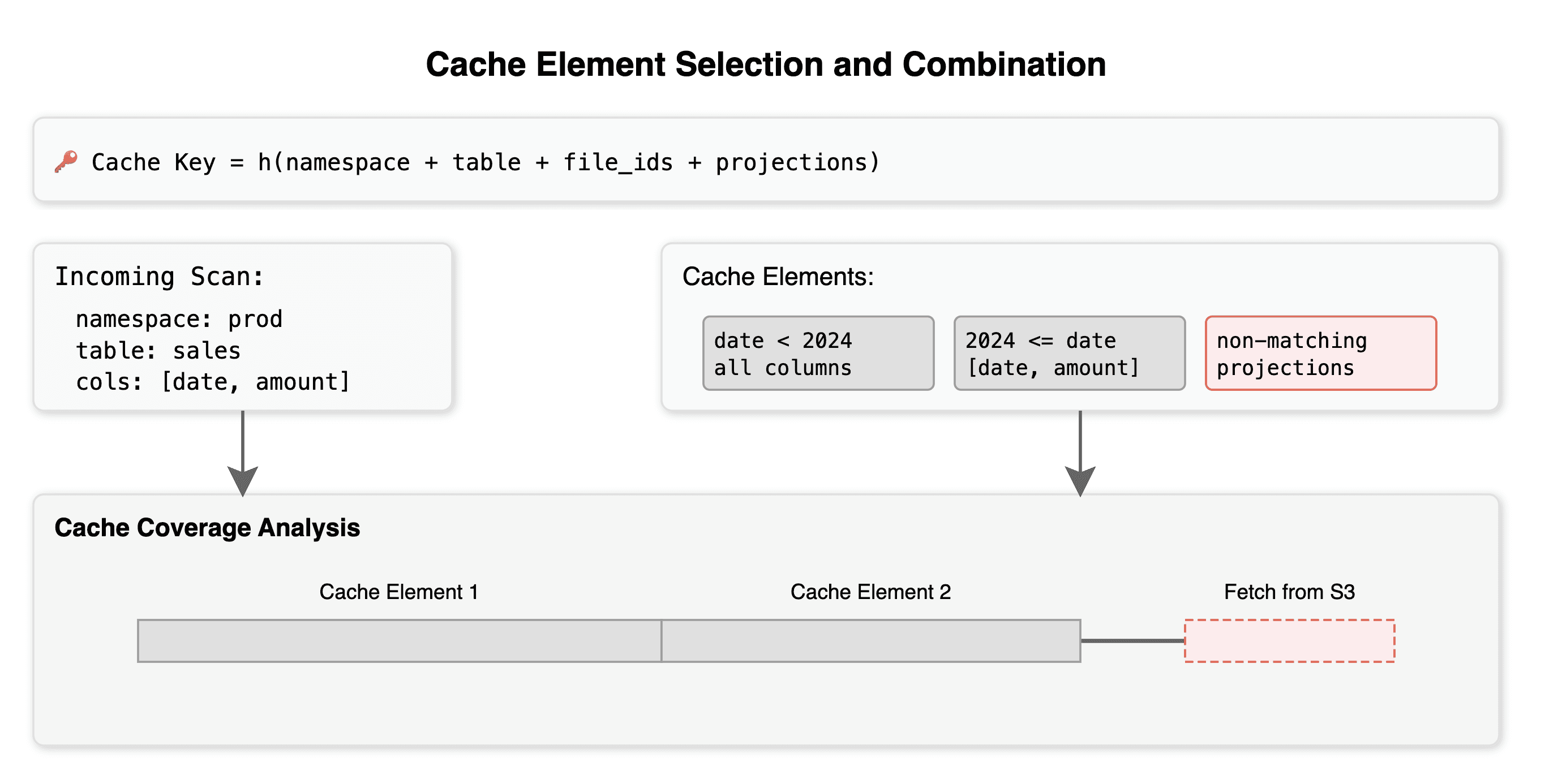
Every cache entry is tied to a specific snapshot of data, as well as a handful of other properties. So if the underlying data changes, the cache automatically invalidates. You will not get stale results.
Our (Bauplan’s) latest paper on this subject (available on arXiv) goes into this in more detail:
For a given scan, the cache is first filtered to contain only cache elements with matching namespace and table, and whose projections are a superset of the scan’s projections. Then, cache elements are applied in a greedy manner... In the best case, cache elements fully cover the scan to be performed, and no communication with S3 is necessary. Otherwise, the parts of the scan that are not covered by cache elements are requested from object storage, and the results are stored as a new cache element. Cache elements with overlapping or adjacent filters can then be combined. Importantly, since scans over Iceberg tables are mapped to an underlying set of immutable Parquet files, cache invalidation is ‘free’: if a table is modified, the cache can deterministically detect which old entries are not relevant anymore by simply storing pointers to original S3 files, together with scan inputs.
In order to persist this cache across runs and different processes in our system, we rely on a variety of mechanisms for persisting the data — for example, shared memory allows passing live data between processes, and results can also be cached to disk locally to avoid needing to publish them back into the catalog. But if we did want to publish intermediate results to the catalog … what then?
Well, stay tuned for our next article in the series talking about materialization.
Try Bauplan Today
That's the power of combining DuckDB and data catalogs. By decomposing the storage and compute layers, you get the flexibility to mix and match as needed. Developers get a friendly SQL and Python experience, while data engineers get the governance and reliability of a production system.
But don't take my word for it. Give us a shout today so you can try it out :)
And if you're curious to learn more about the architecture, check out our docs, or shoot me an email at nathan.leclaire@bauplanlabs.com. I'm always happy to geek out about stuff.




