
Intro
Here at Bauplan, we build a fast, Python-first serverless data lakehouse. What does that even mean?
Our users use our platform to build gnarly data transformation workloads, analytics and Machine Learning pipelines directly on their object storage in the most streamlined way possible. You map out data querying and transformations in SQL and Python, everything's version controlled in your catalog by default, and it feels way more like a natural local workflow than the usual remote shlep you have to deal with, like launching Spark jobs or working in an orchestrator.
We put a lot of effort into making our developer experience with Python really compelling, and one big part of that boils down to making running jobs in the cloud easy and providing a fast feedback loop.
One big thing that gets in the way is that painful process where you rebuild a Docker image, push it, pull it, and restart containers that everyone's probably doing right now.
So we needed to optimize that process by building a Python-native platform that's actually smart about packages and doesn't do unnecessary work when you want to run something with a new package.
Instead of taking hours or minutes to deploy new functions, it takes seconds. Plus all your model results just show up in the data catalog automatically so you can ping your buddy like “Yo, latest DAG run results just dropped”. But I digress.
We are going to talk about some of the lessons learned in the process of building it.
Problem
Before we get into the engineering details let's talk about what problem we're solving here.
Say you're a data scientist trying to build some pipeline with Python steps to make a classifier or even just crunch some analytics or prepare some features for your models or whatever. Usually you'd maybe muck around in iPython or in a notebook locally, then when it's time to ship it to prod you'd have that moment - you know the one - where you look at your coworker like "So... how the heck do we deploy this?"
They shrug and mumble something about Kubernetes and another team. Then fifty tickets later maybe you get it running in prod. Or maybe you're fancy and actually have Kubernetes access, so it's a technical headache that you should probably not have to deal with in the first place.
"Works on my machine, so I'll just ship my machine", right? Let’s go.
If your Python dependencies never change, that’s fine, but Python dependencies change constantly - you're always wanting to try some hot new package or upgrade versions or even switching Python versions entirely.
Even if you know Kubernetes, just adding a new Python module is gonna take forever. You're doing fresh Docker builds every time because yay stateless CI/CD but also oof, stateless CI/CD.
Let’s see, some imperfect napkin math: pulling python takes like 15 seconds, poetry install another 15, docker push 15 more, then Kubernetes has to schedule and pull.
That's like a minute and a half of just waiting around like an idiot. Even with a simpler setup where we use a Lambda instead of Kubernetes, it still takes on average 180 seconds to go end-to-end to change a single package. Repeat that for every containerized unit you have in your application.
With Bauplan? Just update a decorator and run your pipeline against our cloud runtime and the changes will be rolled out in a few seconds.

When benchmarked against warehouse serverless Python and Lambda, adding a new dependency in bauplan is 7-15x faster (check out our recent paper at the WoSc10@Middleware 2024 for details!).

Besides the fact that it’s just nicer to work on a platform that takes care of environments automatically and directly from your code, there are two main situations where our users need a better user experience with containers: prototyping and debugging.
In the first case, a data scientist or a data engineer is iterating many times over a DAG that is being built for the first time or modified from an existing one. In the second case, a data engineer is iterating to see what is wrong with a DAG that is running in production.
In both cases, fast iteration in the cloud is pretty neat, because it doesn’t force you to scale down and work locally which introduces a divide between the staging environment and prod.
If you could do it directly in your cloud environment it would be obviously better, but it boils down to how easy and fast it is.
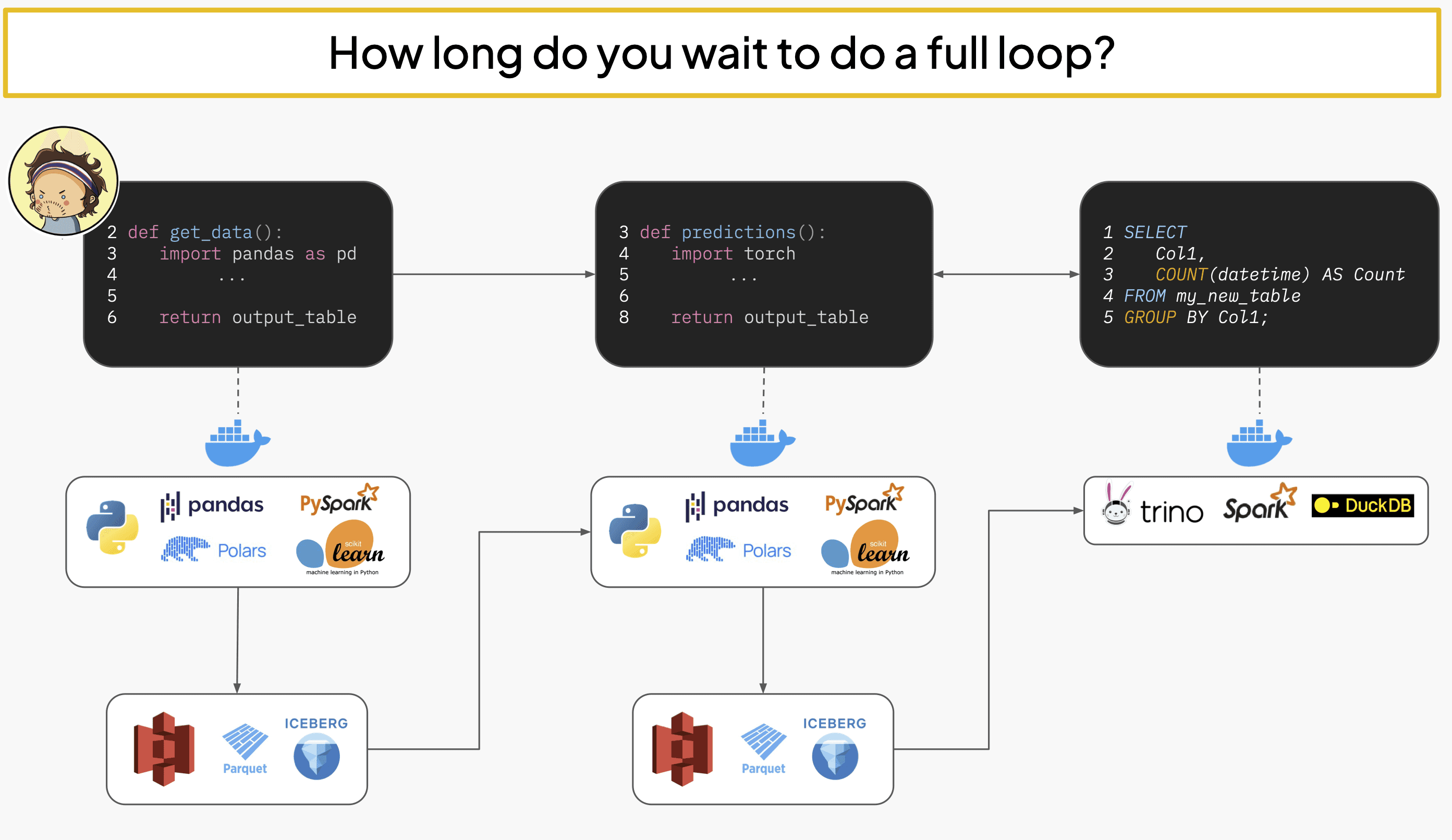
How it Works
"OK we get it, we use your magic platform and it fixes everything, same stuff every vendor says" - yeah, you’re not wrong that we want your money, but let me show you how this magic trick works.
Docker and Kubernetes are good at being these generic abstraction layers that can do, like, anything, but that means they can't be good at specific things. Python packages are a perfect example. When you rebuild the entire world from scratch every time you make your big fat filesystem snapshot, and ship it around with a blunt force instrument like the Docker registry. That’s why stuff gets slow. In our case, we only need to run a tiny subset of "all the things you might possibly want to run on Linux" - basically just serverless Python functions. So we can take some shortcuts.
Our platform has four main pieces:
Client: The command line client / Python SDK.
Commander: The primary API for orchestration that the Client calls.
Code Intelligence: The "brain" that parses user code and plans what to do.
Runner: The actual physical node/runtime that does the things.
So when a user tells Bauplan to do a DAG run, they bundle up their local code and request an allocation to run a "job" that passes various models around. As the first step of this process, we do some planning. Similar to how a query engine works, Code Intelligence looks at what the user wants to do ("Run this SQL query, pass results to this Python function, then to another Python function") and figures out how to decompose that into actual physical steps (usually running Docker containers).
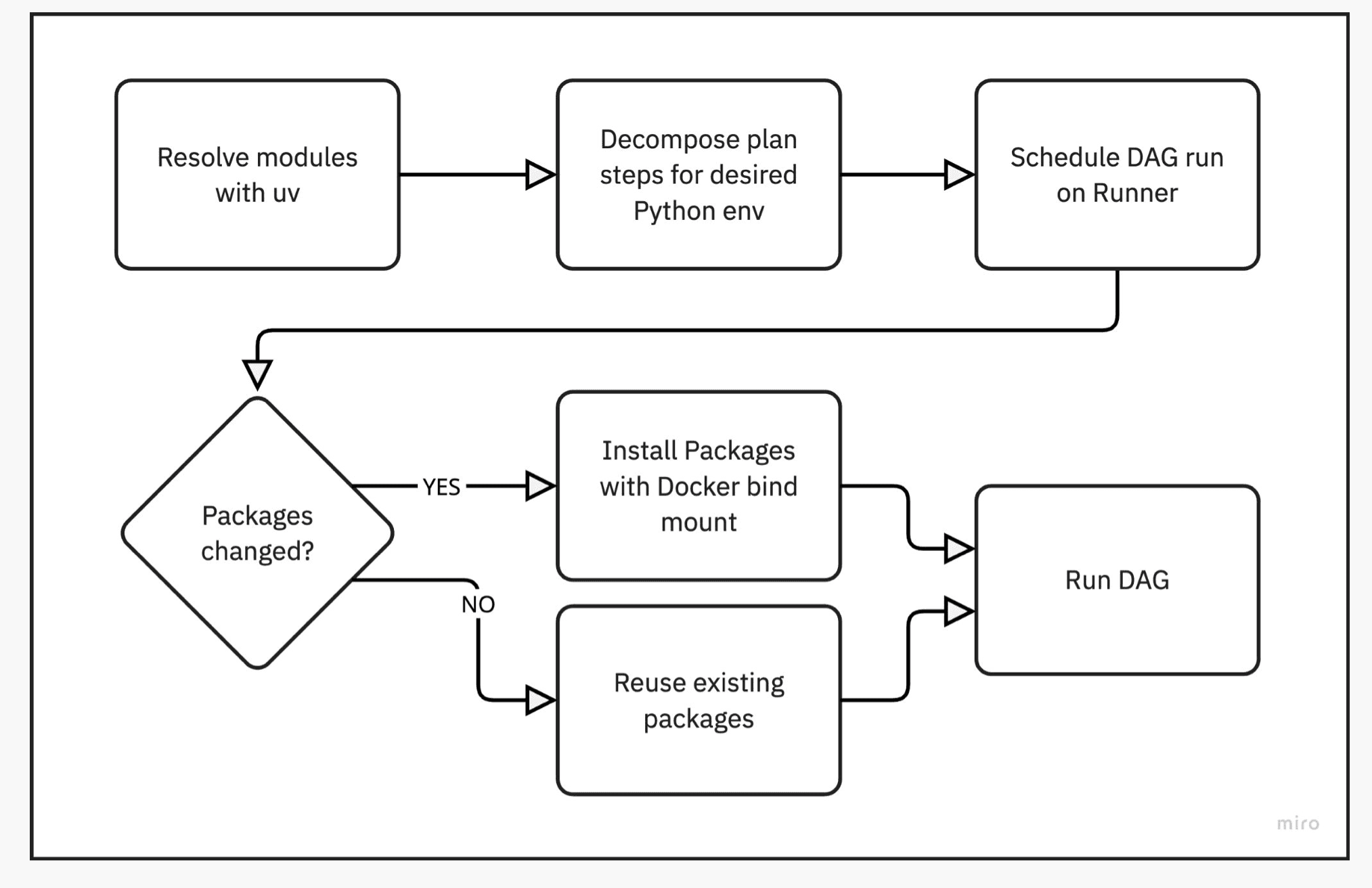
For SQL queries this is super useful because we can be clever about things like scanning ("Oh user only wants customer ID 123... Iceberg can help us know what to pull from S3"), but it's also key to how we handle Python packages.
During planning, we look at what modules the user wants and do resolution using uv, which is this blazing fast modern Python package manager. Code Intelligence spits out a list of modules the Python code will need, spiritually similar to a lockfile from your package manager. At this point we haven't installed anything - we just learn what we'll need eventually.
From that package list, we add steps to our physical plan that the Runner will execute - these end up as Docker containers that install individual packages. Since everything's a DAG flowing from one thing to the next, package installs happen first. Each step basically does a pip install X where X is the target package. Then once they’re all complete, Python step(s) can proceed.
These install steps run in docker using standard Python images, mounting shared directories from the host machine (a big Linux box) for the pip tasks. The user code step that needs these packages gets docker bind mounts (-v /tmp/packages/package_x:/packages/package_x) for each one. We tweak Python paths and config so the runtime finds everything.
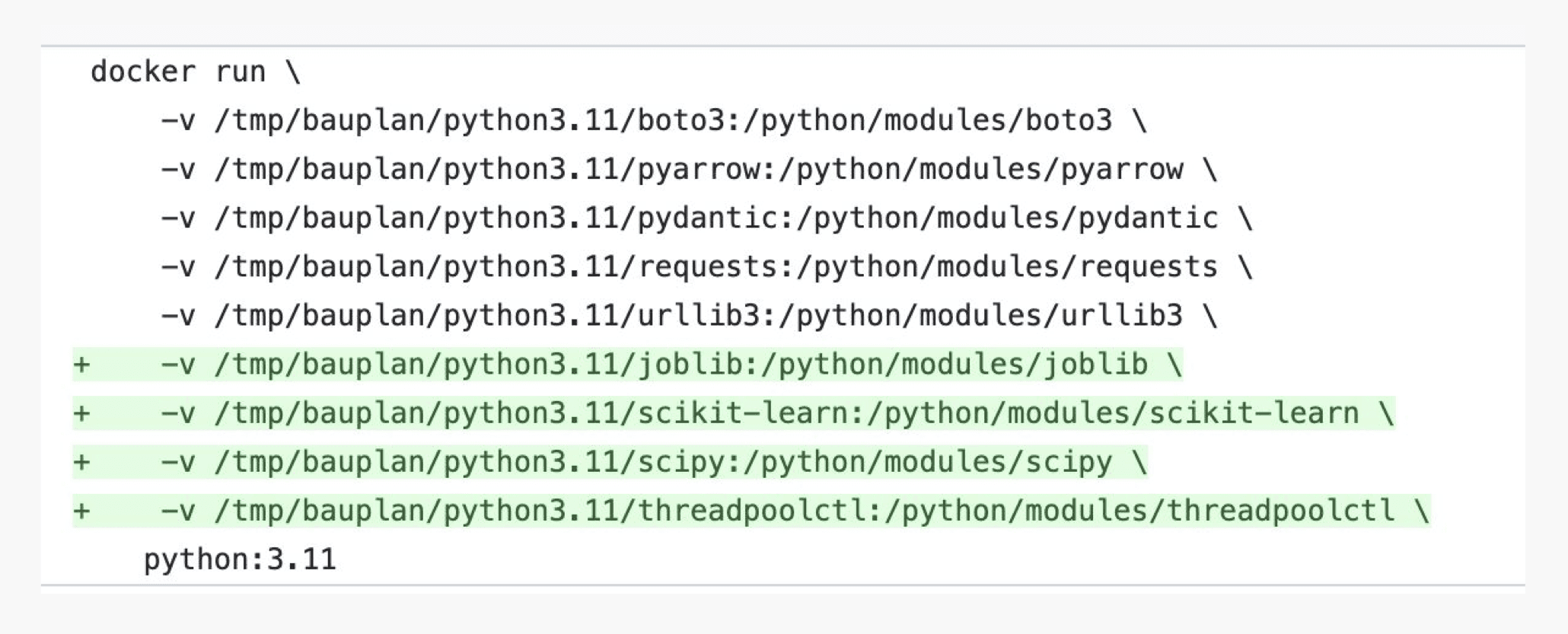
Then when the Python code actually runs, all the packages just show up like they would in a normal script.
This seems simple but the results are amazing - you get god-tier caching and reuse. On the Code Intelligence side, we cache resolution results so the already-fast uv process gets even faster. And for packages in the Runner:
They get reused across runs of the same stuff - you only install a package once unless it gets pruned for being unused. No pip modules changed? No rebuilding needed.
They get shared between different models using the same packages - if three functions use pandas 2.0, we install it once, not three times. The planner optimizes it out.
They're differentially efficient - adding or changing packages only updates what actually changed. So you can rapidly try different versions and packages without suffering through endless CI/CD builds.
Acknowledgment
Many of the fundamental intuitions about this came from the work from the folks at Open Lambdas and from the collaboration between Bauplan and Tyler Caraza-Harter and Remzi Arpaci-Dusseau and at University of Wisconsin-Madison.
Try Bauplan
So yeah, that's one of many cool optimizations that make our fast, Python first super easy to use serverless data lakehouse the next big thing. Want a platform where all your data is versioned forever, totally collaborative, with wicked fast data scanning and Python that doesn't make you want to tear your hair out?
Try our platform and let us know what you think.
Love Python and Go development, serverless runtimes, data lakes and Apache Iceberg, and superb DevEx? We do too! Subscribe to our newsletter.
