
This is a blog post version of the most salient concepts I presented at the MLOps Days NYC hosted by Jfrog and the MLOps Community.
Over the past four years, pre-trained models like GPT have radically simplified how companies use ML and AI.
One huge advantage of pre-trained models is that, rather than doing everything from scratch—gathering data, building, training, and maintaining models yourself—you can now simply tap into incredible inferential capabilities through a simple API. This drastically simplifies what otherwise makes MLOps special and hard.
The consequence of this is that, for the first time, regular software engineers without a strong background in ML can incorporate AI capabilities into their applications. I remember our revelatory moment when ChatGPT first came out. My phone lit up with messages from colleagues and friends curious about machine learning for the very first time. Most of them were software engineers without ML backgrounds who suddenly realized: "Hey, I know what an API is, I can see how to build something with this!"
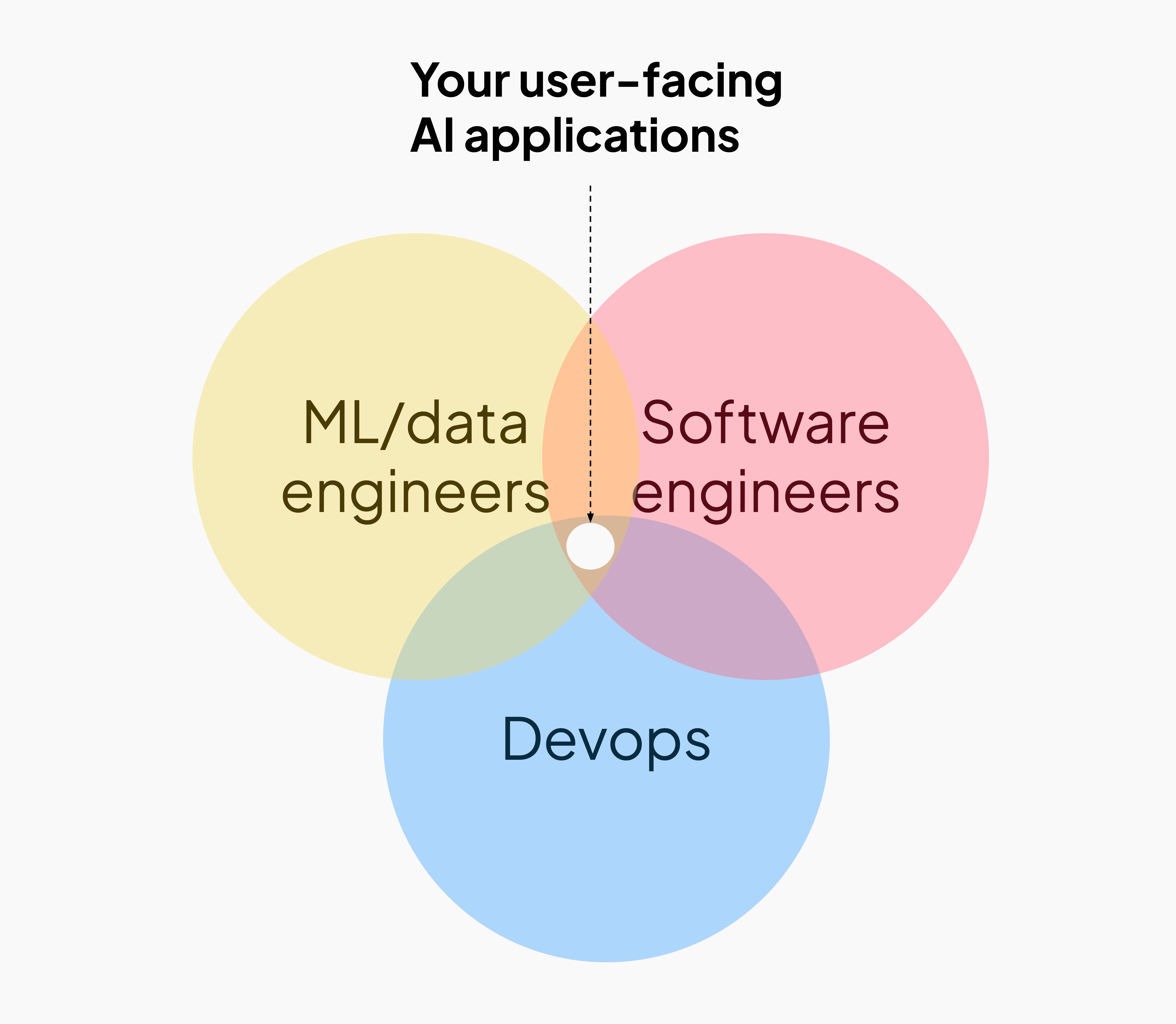
This accessibility marks a critical shift from more traditional data science, where predictions and models are often done in Jupyter notebooks, built primarily for internal analyses rather than user-facing use cases. Now, AI is deeply embedded in applications that directly serve end-users, like Conversational Agents, Recommenders or RAG systems.
Because of this shift, AI is increasingly becoming just another software engineering problem, and as such, it needs to embrace software engineering best practices like modularity, test driven development, and CI/CD.
Since AI workloads become easier to build and maintain, organizations should be able to rely more on their existing developer teams rather than creating large ML and data engineering teams. Ideally, a few ML developers can work with existing teams of DevOps and software engineers, instead of treating AI as a “special case”, different from everything else.
Big-Data frameworks are just weird
The main bottleneck that I see today for this to happen is not AI tools: is data platforms. Even though the models have become easy to use, we still need a data platform to run the entire life-cycle of our AI applications. For instance, we still need to ingest, clean and transform data, we still need to do some training and fine-tuning, and we certainly still need data lakes to allow developers to work on real data while enforcing governance policies and protecting the production environment from disruption.
The most widespread data platforms out there are not designed with a software engineering mindset in mind and are built for Big-Data problems that most organizations don't have. Most organizations are dealing with data at what I call "Reasonable Scale". They're working with gigabytes or terabytes of data, not petabytes; they have dozens of ML engineers, not hundreds; and they're solving complex but well-understood problems like recommendation systems, fraud detection, or conversational agents. For these teams - which represent 99% of all AI projects - the overhead of distributed Big-Data frameworks creates more problems than it solves.
Let’s take Spark as the most eminent example. Spark is flexible and powerful, but from a software engineer’s perspective, it is pretty weird.
Deployment, Maintenance, and Testing: deploying Spark involves managing clusters, fine-tuning resource allocation, and handling complex infrastructure that isn’t straightforward for standard software teams. Debugging distributed jobs often requires specialized knowledge—your familiar debugger isn’t useful when Spark runs code distributed across multiple nodes.
Testing Spark jobs is tricky because the code’s behavior heavily depends on the input data and cluster environment. Developers often resort to complicated setups (local Spark instances or small sample datasets) just to simulate cluster behavior for simple tests.
Continuous Integration/Continuous Deployment (CI/CD) isn’t naturally integrated into Spark. Unlike web apps or microservices that seamlessly fit into automated CI/CD pipelines, Spark requires significant manual work like building custom artifacts, managing configuration, and orchestrating deployments through external scripts and complex tooling.
Spark's programming model itself is peculiar. It uses lazy evaluation, meaning transformations on data don’t execute immediately. Developers must understand new concepts like distributed datasets (RDDs or DataFrames), partitioning, and shuffling data. Standard debugging tools become less effective, forcing developers to adapt to specialized workflows and UI-based debugging tools.
Notebook reliance is a hallmark of traditional data platforms and introduces further complications. While notebooks are excellent for exploratory tasks, they’re problematic in structured engineering environments because:
They encourage ad-hoc development rather than modular, testable code.
Execution order isn't guaranteed, causing hidden dependencies and reproducibility headaches.
Version control is a nightmare. Tracking changes or reviewing code becomes difficult when code, outputs, and documentation intermingle in the same notebook. Collaboration suffers due to tricky merge conflicts.

Data as Software: a code-first approach
So let’s build a data platform that can be understood by all kinds of developers and allow us to follow well-established software development practices. Where do we start?
First, data platforms should stop being weird and start being code-first like every other mature tool for developers. GUIs, Notebooks, and drop-down menus are great for the citizen data scientists and analysts, but if you want to build actual software applications, we are going to need the usual acronyms: IDE, TDD and CI/CD.
Second, we want to rely upon concepts that every developer already knows. The cost of learning new things is actually one of the highest costs we pay as developers. If a platform requires too many concepts to be learned, it will make developers ramp up longer, and the future costs of switching very high.
To design Bauplan we followed this principle pretty religiously: if a fresh-outta-school CS graduate might not know what it is, you need to justify it.
Not every one knows what a Spark session is, but everybody knows what a Python function is. Not everyone knows about Containers and EKS, but everybody knows what a package is. Not everyone knows what parquet files and data lakes and Iceberg Tables and Hive Metastores are, but everyone knows what a table with columns and rows is.
Even fewer people will know what a Medallion architecture or a Write-Audit-Publish pattern is, but everyone understands Git concepts like branches, commits and merges.
Run it like a script
Let’s consider an example. Imagine you have to process a large dataset and clean it up for analysis. This is what it would look like to do it using Pandas leveraging Bauplan as a cloud runtime:
Let’s run it:
All the infrastructure details are abstracted away and no DSL is needed. We don't need to know how this function will be run to write the code or to have a JVM setup anywhere. We don’t even need to understand containers to use Pandas 2.2.0 in this function. The system takes care of running this function in the cloud and handling all the infrastructure. For the developer it is just a function.
This function is vertically integrated with S3, which allows us to read and write tables in our data lake, without having to know any details about the implementation of the input dataset. We don’t need to know whether this is a csv file, or a Parquet file or a bunch of Parquet files, or an Iceberg table: we only need to know that it is a table with columns, rows and filters.
Every developer with basic familiarity with Pandas will look at this code and will be able to guess what it does. Oh, you never used Pandas? Ok, how about writing the same function in SQL using DuckDB?
Bauplan does not tell us which packages to use, or which tables to read, or when to write back a table into S3. That is our code and our preferences, the platform will run our code, move our data around and make sure that we don't have to bother with implementation details.
Adding Git for data
Let’s now write this new cleaned dataset back into our data lake. While doing that, we want to make sure that this does not impact our production data though, because several other systems depend on those.
We are going to use a very simple workflow that looks and feels exactly like a standard software engineering workflow using Git. We are going to create a branch of our data lake as a zero-copy operation, run our function in that branch and write a new table called clean_dataset in that branch and then explore the schema of the new table. All using just a few git-like commands from the CLI:
And finally automate
Thanks to these abstractions, working with your data pipelines becomes part of a familiar Git workflow that can be easily programmed and integrated in a CI/CD pipeline by simply using an SDK instead of the CLI.
The code above, represents the structure of a Write-Audit-Publish pattern but instead of being a exoteric data-infrastructure-specific concept, it becomes a simple Python function. How hard is it to guess what this code does when we look at it for the very first time?
Wrapping up: simplify, write code and automate
AI today can’t be a siloed experiment—it needs to be a production-ready part of your software ecosystem. To scale AI in your products, we all need data platforms that can support well established software engineering principles. This is best achieved by moving beyond notebooks, overly-specialized frameworks, and complex deployment architectures.
In other words, make your data platform behave more like software so your developers can approach ML/AI development as they would any other software development—structured, reproducible, versioned, and thoroughly tested.
This philosophy is the heart of a new generation of data platforms: by using common concept that every developer knows (functions, packages, tables, and version control) developers can build AI applications that are robust, scale gracefully, and deliver measurable business value, no matter the size of your team or data.
At Bauplan, we believe that data and AI engineering will progressively become part of software engineering. And if there’s one lesson we learned well it’s this: never bet against software.
Love Python and Go development, serverless runtimes, data lakes and Apache Iceberg, and superb DevEx? We do too! Subscribe to our newsletter.
