Embedding-based Recommender Systems with Bauplan and MongoDB


Introduction
View in Github.
In this example, we’ll build a full-stack embedding-based recommender system in around 200 lines of clean, no-nonsense Python, using Bauplan for data preparation and training, and MongoDB Atlas for real-time recommendations.
The aim is to build a production-grade pipeline directly on object storage, without getting bogged down by cloud APIs, container orchestration, Iceberg quirks, Spark clusters, or EC2 provisioning.
Why is this important? Because robust AI applications sit on end-to-end data platforms which are hard typically to build and maintain.
As an example, the recommender system we showcase in this article goes from raw, high-dimensional data to be transformed into some low-dimensional representations like embeddings, and different models with different architectures to be trained, tested, stored and cached for inference.
To do this we need to deal with data – sampling, cleaning, quality testing, feature engineering, and model training, and with compute – provisioning machines, configuring clusters, containerizing environments, and managing libraries.
Since ML systems are so complex, it is critical for developers to aim at platforms that drastically reduce complexity without sacrificing robustness.
A good platform should allow us to use the right data structures with the right compute while wasting zero time wrestling with the infrastructure.
Bauplan + MongoDB attains precisely this goal.
- Bauplan is a serverless python-first lakehouse platform that allows you to run complex data workloads in the cloud with the same intuitive ease you’d expect from your local machine. In this repo, Bauplan takes care of running the code, isolating the environment and moving the data from S3 into Atlas while ensuring that intermediate artifacts can be persisted if needed and that all tables can enforce schema evolution, and be automatically versioned throughout the process.
- Atlas makes it extremely easy to do the list mile thanks to its flexible document model and unified query interface: embeddings can be quickly stored and indexed to do real-time interrogation with just a few lines of Python with Pymongo.
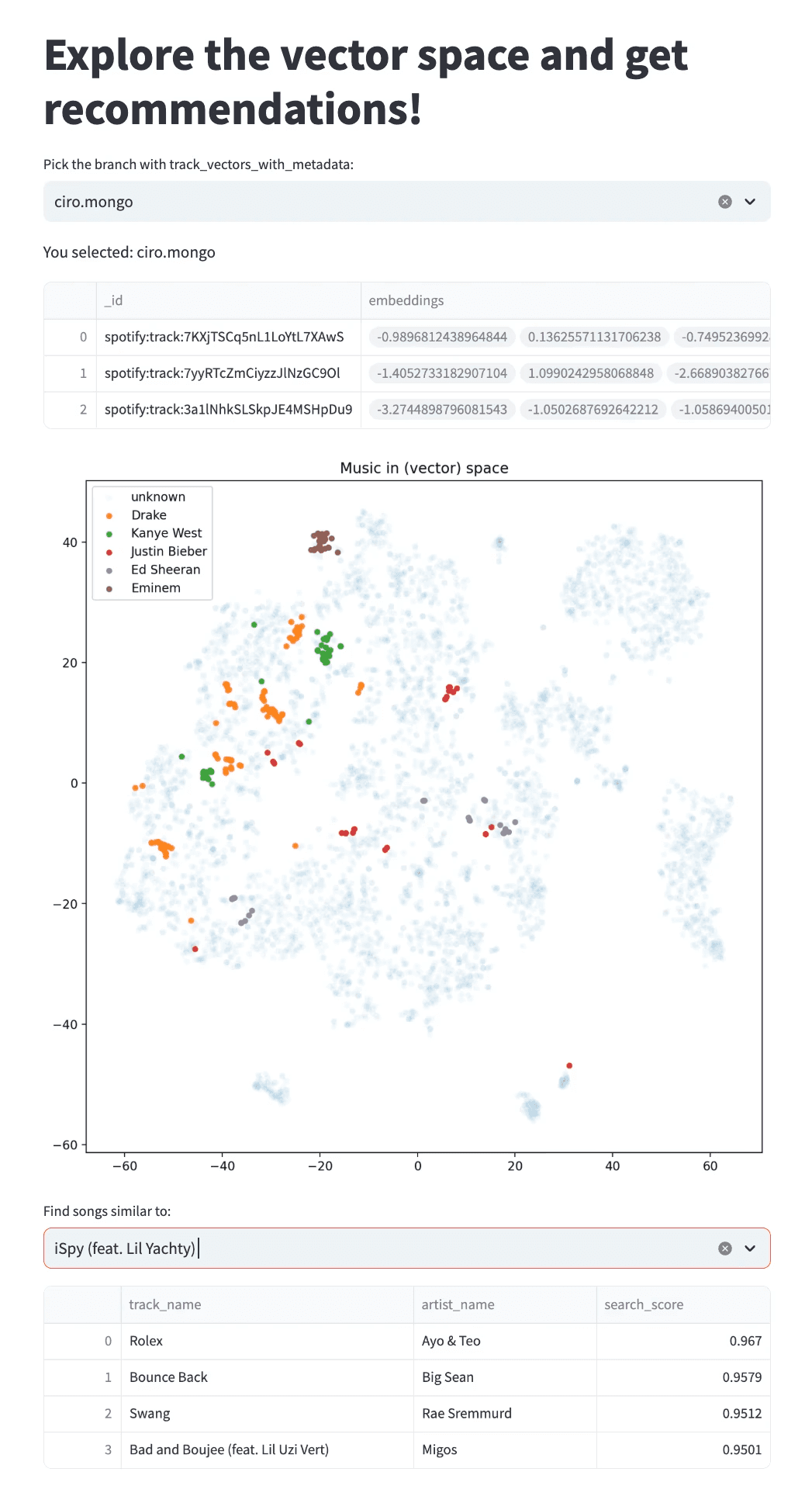
The model is trained on Spotify Million playlists Dataset and we use a Streamlit App to explore the track embeddings and the recommendations.
Buckle up, clone the repo and sing along.
How does it work?
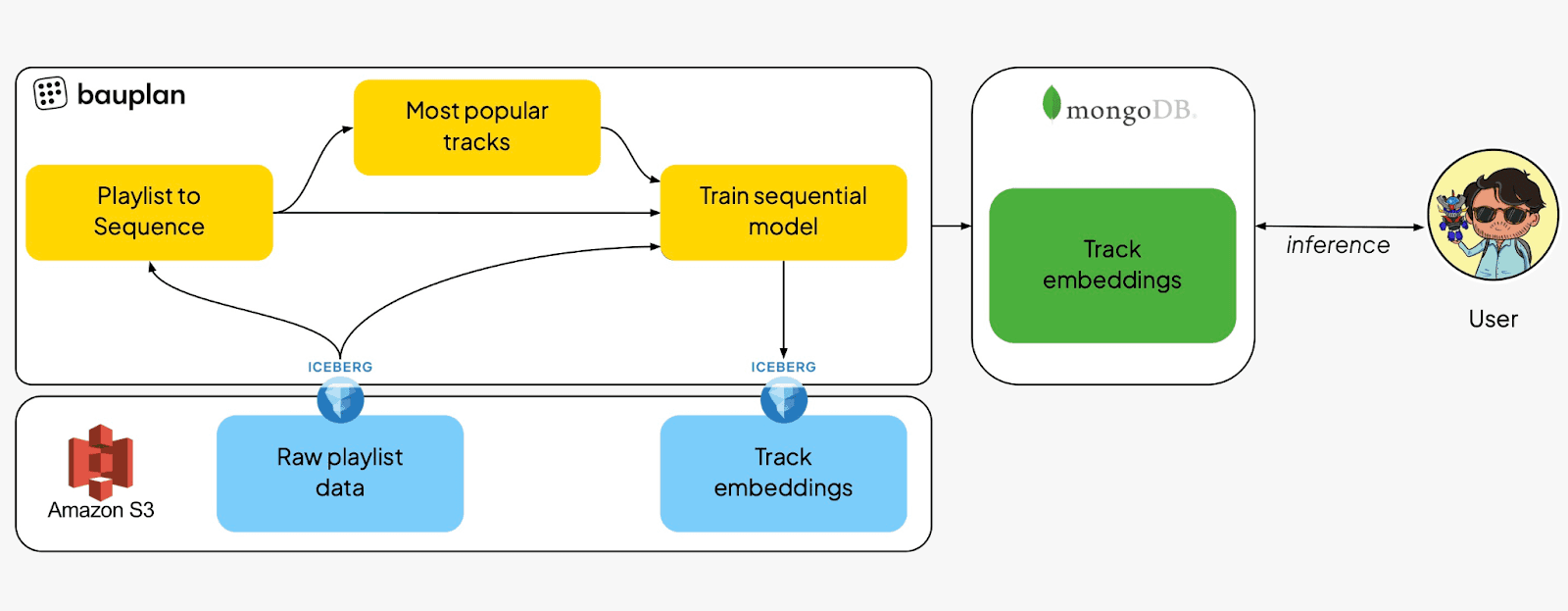
At a high level this is how our recommender system works. Raw data is stored as Parquet files in S3. Those parquet files are imported as Iceberg Tables using Bauplan – the tables for this example, are already available as public tables in Bauplan’s sandbox.
A data transformation pipeline is triggered as a bauplan run. In this pipeline, the data is fetched from S3 and manipulated into sequences of track IDs based on the playlist order, resulting in an intermediate table of two columns:
Playlist to sequence

Then, the most popular tracks in the playlist tables are computed, resulting in the intermediate table of two columns:
Most popular tracks

Finally, a sequential model on track sequences is trained on the data to yield a final table with embeddings for each track, including a column with 2-D embeddings to make the visualization in the streamlit app possible
Track embeddings with metadata

In this final node, the embeddings are shoved to a MongoDB collection where a vector index is constructed: at inference time, this is the very index we will query to retrieve recommended songs similar to DNA for example, using the distance in the vector space as our similarity metric.
Finally, the embeddings and the recommendations can be visualized and explored in our Streamlit app. Note that the visualization embeddings depend on the branch in which we decided to materialize the final Iceberg table.
Why Bauplan and MongoDB Atlas?
This embedding-based recommender system is a clean, no-frills showcase of an end-to-end ML application—spanning data management, transformation, ML operations, and juggling multiple data structures and compute resources.
By combining Bauplan and MongoDB, we can seamlessly integrate data preparation, model training and serving recommendations in real-time. Bauplan makes it extremely easy to build and run full-fledged data pipelines directly on object storage. In this example we use it to i) read-from / write-to S3 with Iceberg Tables while spinning up isolated, sandboxed data environments in the data lake and ii) transform data with Python functions, enjoying total freedom to mix and match dependencies–wrangling data with DuckDB, preparing embeddings with Gensim and Scikit-Learn, and storing results into MongoDB via PyMongo.
Meanwhile, MongoDB Atlas seamlessly handles document storage and search. Data flows into the document store, where a vector index works its magic at inference time for fast, efficient retrieval.
At no point do you need to think about infrastructure. Zero, zip, zilch, nada. Your entire business logic lives in a single Python project—run it from anywhere against Bauplan’s API, and let the system take care of the heavy lifting: zero-copy clones, containerization, caching, data movement.
Moreover, both platforms are extremely easy to program. In this example, we showcased this point by using both Bauplan and Mongo’s Python clients to build a simple Streamlit app.
However, the same simple SDK-based integration applies when it comes to integrating the capabilities of your end-to-end ML stack into orchestration and CI/CD workflows, which become fundamental when your system is in production serving recommendations in the real world every day.
Try it out
Ship your first application with Bauplan and MongoDB Atlas.




