
View in Github.
Retrieval-Augmented Generation (RAG) has emerged as one of the most powerful techniques for building intelligent applications powered by large language models (LLMs). By augmenting generative models with real-time, external knowledge retrieval, RAG overcomes a fundamental limitation of LLMs: their inability to access information beyond their training data.
Implementing an end-to-end RAG pipeline involves multiple moving parts—data processing, embedding generation, vector storage, and retrieval—each of which can introduce complexity and infrastructure overhead.
In this example, we’ll build a full-stack RAG system in around 300 lines of clean, no-nonsense Python, using Bauplan for data preparation and management, and Pinecone for real-time retrieval.
As usual, the code will speak for itself, so clone the repo and dive in!
Unpacking RAG Systems
At its core, RAG combines retrieval-based models with generative models to enhance response quality. While LLMs excel at generating text, their biggest limitation is the inability to access domain-specific knowledge not included in their training data or prompts.
RAG addresses this by introducing an external knowledge retrieval step:
User query → Receive text from a user and generate an embedding (a numerical representation of the text).
Retrieve relevant documents → Search a vector database for embeddings closely matching the user’s query from an index of existing documents.
Generate response → Insert these relevant embeddings as "context" into the prompt provided to the downstream LLM, enabling it to produce a more informed, context-aware response.
With this approach, RAG systems can answer questions with real-time, accurate, and highly relevant information. It's essentially search on steroids.
To build a production-ready RAG system, we need two essential components:
A powerful yet simple data processing framework (to prepare data, generate embeddings, and manage pipelines).
A scalable vector search engine (to efficiently store and retrieve relevant knowledge).
That’s what we put together in this repository:
Bauplan is a serverless data processing platform designed specifically for AI applications. In a nutshell, it allows developers to run Python functions directly against data in S3 in the cloud, chaining these functions together into sophisticated data transformation, analytics, and AI pipelines without worrying about containers, cluster configuration, or performance optimization. Additionally, Bauplan’s function-as-service runtime is vertically integrated with your S3, so data management comes built-in, and data is automatically version-controlled in an Iceberg catalog by default.
Pinecone is a vector database. It enables fast and efficient similarity searches for embeddings, optimized for real-time retrieval. Pinecone returns results in milliseconds, even with millions of embeddings, and effortlessly handles massive datasets.
Both services are fully managed, removing infrastructure complexity from this implementation.
Our Use Case: Self-Service Support Agent
Let’s work with a real-world dataset: Stack Overflow Q&A data. We’ll build a self-service agent that helps users find answers from historical Stack Overflow support tickets.
Our implementation consists of three components:
Bauplan to preprocess, clean, and generate embeddings for historical Q&A data.
Pinecone to store embeddings and handle real-time retrieval.
Streamlit app to provide a user interface for queries and deliver AI-powered answers in real-time.
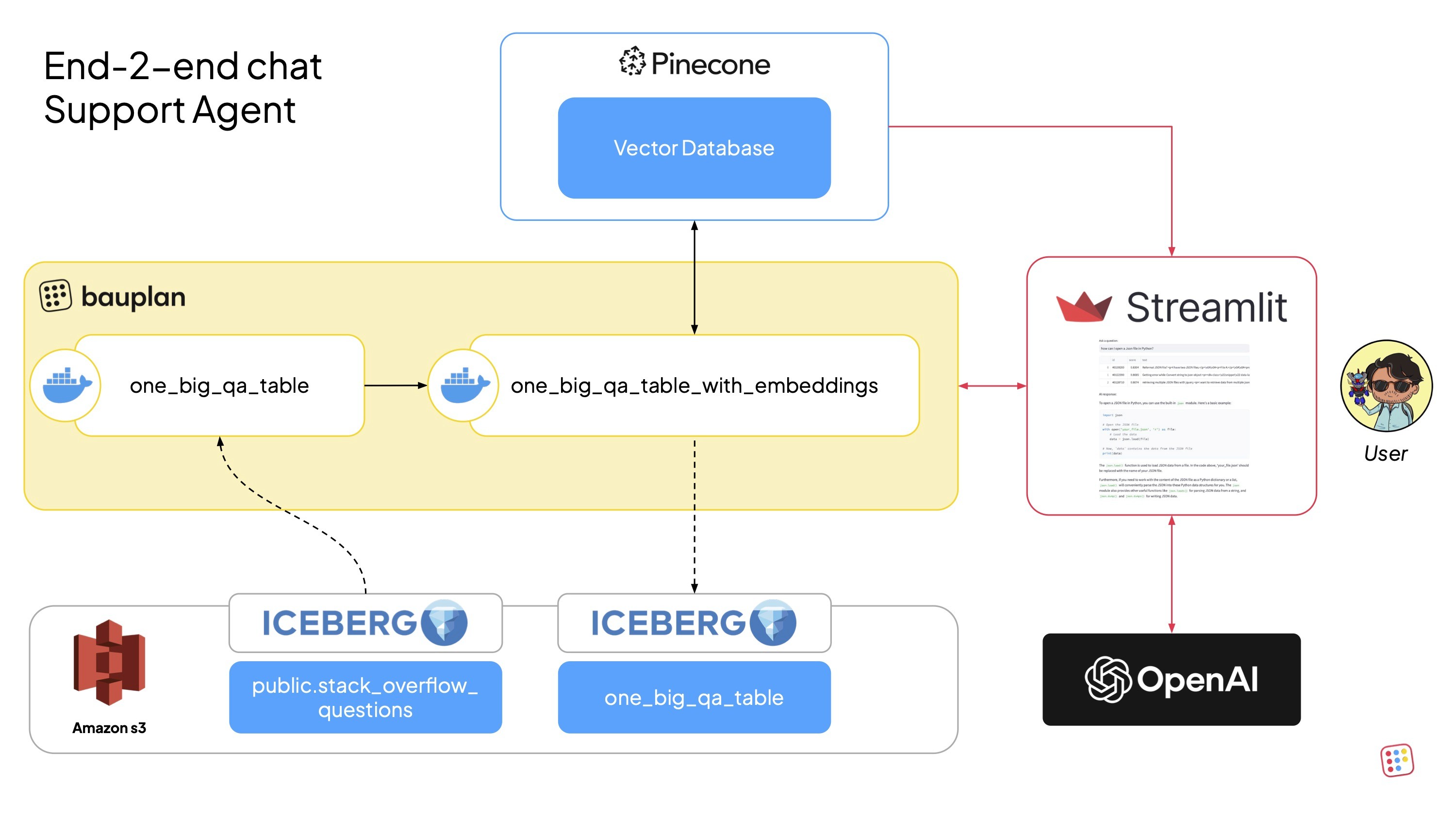
How It Works: the End-to-End RAG Pipeline
Here’s how data flows through our RAG system:
Ingest Q&A data. The dataset is stored in Bauplan-backed Apache Iceberg tables.
Process and generate embeddings. Bauplan pipelines transform and vectorize text data.
Store embeddings in Pinecone. Processed embeddings are stored in a high-performance vector index.
Query in real-time. When a user asks a question, Pinecone converts the query into an embedding, searches for similar embeddings, and retrieves the most relevant answers and OpenAI’s GPT-4 generates a final response.
User feedback. Finally, the user receives a fully contextual, AI-generated answer.
Now, users can explore the vector space created in Pinecone, representing the most representative topics in the dataset (e.g., Python, JavaScript). Finally, users can ask natural language questions and receive instant, AI-generated answers through OpenAI GPT-4 directly in the Streamlit app.
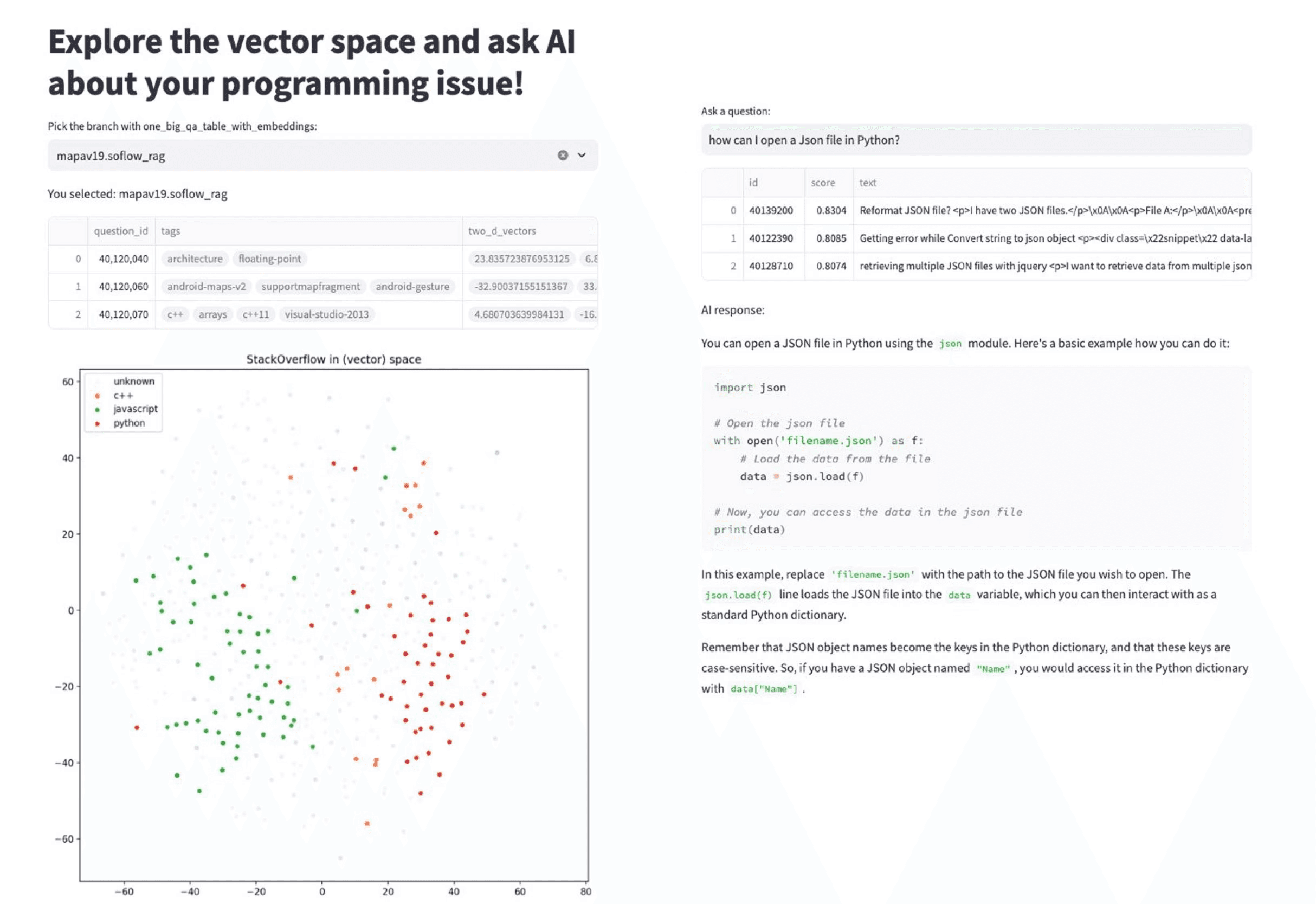
Ta-dah! This is one of the simplest yet most powerful ways to build a fully functional, production-ready RAG system.
Try It Yourself
Clone the repo, start hacking, and build your own RAG system today!
Love Python and Go development, serverless runtimes, data lakes and Apache Iceberg, and superb DevEx? We do too! Subscribe to our newsletter.
