To serverless or not to serverless



A common problem is building modern data systems is balancing ease of use and developer experience with cost containment and maintaining control over your infrastructure.
In our past work, we faced this tradeoff firsthand. Hiring skilled engineers, especially ML talent, was challenging, so we needed systems with quick ramp up and high retention—without blowing up our budget too much.
At least for analytics, Serverless solutions like Snowflake offered us much better developer experience but at the price of high compute costs and reduced (almost no) control.
When designing Bauplan, we revisited this dilemma, this time with the idea of building natively for object storage and data lakes.
That led us to explore whether we could achieve the benefits of a Serverless programming model with alternative compute models, like single-node, on-demand EC2 instances. So we decided to write about some of the explorations we made.
Spark and Data Lakes
The promise of data lakes has always been: “Here’s some raw data—wrangle it into the shape you need and perform complex operations on it.” Object storage has made this even more appealing by offering cheap, infinitely scalable storage—exactly what data lakes were designed for.
In our experience, 90% of those building data lakes on object storage choose to run Spark clusters in their cloud. Spark offers enough flexibility to implement good control, and cost optimization, along with familiarity—it’s a widely-used framework. Moreover, it’s one of the few frameworks out there that allows for more than just SQL, which is increasingly important since AI and ML are mostly done in Python.
So, since at bauplan we are more interested in data lakes, data lakehouses and object storage we are going to talk about Spark more than Data Warehouses in this post.
The problem with Spark is that it has a notoriously clunky developer experience. Every data scientist has been there: waiting 10 minutes to even start asking a simple question like “how many API calls with XYZ features did we receive yesterday?”, because Spark clusters are slow to spin up. This is problematic for two reasons.
- The first is that fast feedback loops are one of the main factors for developer productivity.
- The second is that slow startup time makes Spark clusters poorly suited for synchronous workloads - such as ad hoc queries, real-time analytics, or feature computation. So teams are forced to maintain always-on clusters to support these use cases, increasing complexity and driving up costs.
Serverless to the rescue
The main alternative to this more traditional paradigm is represented today by what is usually called the Serverless model: on-demand compute can be made faster to access and easier to use by using warm pools of machines managed in a multi-tenant environment. In other words, to remove the startup time cloud vendors provision excessive capacity and then dynamically allocate it to customers whenever they ask for it.
The advent of serverless options is very exciting for a number of reasons. In fact, the best Spark company out there, Databricks, announced the release of Serverless at their Data + AI 2024 conference, and rightfully got a lot of attention.
In a very insightful blog post, the folks at Sync Computing compare Databricks Serverless to their traditional Spark offering to conclude that “A great use case for serverless, which we fully endorse, is using serverless for short (<5 min) jobs. The elimination of spin up time for your cluster is a massive win that we really love.”
Serverless can help with removing complexity and simplifying the stack design. As mentioned, Spark clusters do not do well with synchronous workloads where users are waiting for an answer on the other side of the screen and as a consequence data systems in enterprises tend to be split in two.
One part of the stack is for asynchronous jobs, such as batch pipelines, while the other is for interactive queries and real-time use cases and requires clusters to stay warm 24/7. If we had on-demand Spark with no spin-up time, we wouldn’t need this separation [2].
Third, Serverless is supposed to help with eliminating the constant need for configuration that Spark requires to prevent inefficiency and resource waste.
The argument in favor of Serverless is that, by reducing idle clusters and avoiding overprovisioning, we can ultimately be more cost-effective without manual optimization.
It is a plausible argument, but it may not hold up when tested empirically. As pointed out in the same piece by Sync Computing, “even though Serverless does not have spin up time, the cost premium for Serverless still equated to roughly the same overall cost — which was a bit disappointing”. [3]
One critical point we want to emphasize is that the high costs associated with the Serverless model are not just a result of vendor whims. Instead, they stem from the inherent structural design of serverless architecture, which requires maintaining a warm pool of machines to connect to workloads on demand, leading to significant expenses.
Finally, removing all control over the runtime of your jobs also makes compute costs entirely determined by the vendor, which is obviously less than ideal - especially considering that enterprises can often leverage their existing cloud contracts to depreciate their marginal costs.
Serverless options clearly offer improvements for specific challenges, such as accelerating the developer feedback loop. However, their benefits are less apparent for issues related to cost control and balancing simplicity with expenses and for a number of use cases it still makes total sense to have your compute running in your own cloud.
So, what if we looked for a different tradeoff? One that could accommodate DX and cost optimization? What if we tried to find a way to remove the startup time while still using good ol’ EC2s on demand in our own cloud account?
Reasonable Scale and Single Node (or, against the inevitability of Spark)
Spark came along as a developer friendly system (which it was, compared to Map Reduce!) to run data across multiple machines in a world where distributed computing was necessary to overcome the limitations of CPU and memory in the cloud.
This argument did not age well, for a simple reason: cloud compute capacity grew much faster than the size of datasets. Spark started in 2009 when the newly announced AWS EC2 High-CPU instance types c1.xlarge had 7GB of memory and 8 vCPU [4]. Today, dozens of TBs are easily available with almost 10.000x those 2009 figures and that is enough to accommodate most of the workloads out there.
Based on our totally personal, opinionated, biased, unfiltered experience and hundreds of conversations in the space, not many table scans in enterprises go over that size. Most workloads are actually at “reasonable scale”. [5]
Spark is great but it is also famously hard to maintain and to reason about due to the complexity of the API, the cumbersome JVM errors and to the fact that it is often a struggle to view the intermediate results of multi-step processing pipeline at runtime.
So, given that compute instances are big enough to fit most of our jobs, we might want to choose simpler single-node architectures over Spark, and where possible, pick simpler alternatives in SQL (e.g. DuckDB) or Python (Pandas, Polars and Ibis). [6]
Removing startup time in in-your-cloud
To approximate the experience offered by Serverless while using single-node instances in our own cloud we need to address the problem of startup time: let’s say that we could obtain a startup time that ranges between 10 to 15 seconds.
It would be a much longer cold start than, say, AWS Lambda, but it would be a 30x improvement compared to the 5-7 minutes of standard EMR / Databricks clusters. Data workloads are rarely that latency sensitive: 15 seconds sounds pretty reasonable if we are running queries that may take more than 45-60 seconds just because of the time needed to scan 20GB in object storage. Moreover, a 15-second startup is probably fast enough to maintain a developer's mental flow, which is very important for developer productivity .
Surprisingly, we can achieve efficient, low-latency data processing on our own EC2 instances by combining the following strategies.
- Replace Spark with a High-Performance, Vectorized Single-Node Engine. Engines like DuckDB or DataFusion running on a sufficiently large EC2 instance offer several advantages over Spark:
- In-memory processing:
Operating on a single node allows data to remain in-memory and local to the process, reducing I/O and avoiding the overhead of distributed communication. - SIMD and OLAP: vectorized engines process data in batches using Single Instruction, Multiple Data (SIMD) instructions. This means they can perform the same operation on multiple data points simultaneously, greatly accelerating query execution—especially for analytical workloads typical in Online Analytical Processing (OLAP).
- Fast Startup & Low Latency: No cluster provisioning means instant query execution, which is just better for interactive workloads.
- Simplified Architecture: No node failures, network issues between nodes, or complex cluster management, makes the system easier and cheaper to operate.
- In-memory processing:
- Pick high-bandwidth EC2 instances co-located with S3 (and use Arrow). This way we can optimize data transfer and ensure that large datasets can be moved quickly between storage and computation layers. By using Apache Arrow as both the in-memory and over-the-wire data format, we optimize data serialization and deserialization processes. Arrow's columnar in-memory format is designed for efficient analytical operations and can be shared between processes without costly data conversion. This setup speeds up query execution and reduces overhead.
- Employ Purpose-Built Operating Systems Like Unikernels. Unikernels are minimalistic, single-address-space machine images that include only the necessary components to run your application. They have significantly smaller footprints, leading to faster boot times compared to standard operating systems. This reduces the cold start time of your EC2 instances.
Cold starting an 7i.8xlarge EC2 instance to run query 13 (\~12 seconds to start processing from scratch).
These are 22 TPC-H queries (factor 100), run one after another in our own AWS fully on-demand for each query - i.e. before “sending a command” and after receiving the results no EC2 is billed. For comparison, we also run all the queries on a warm instance to more easily disentangle query runtime from spin up time.
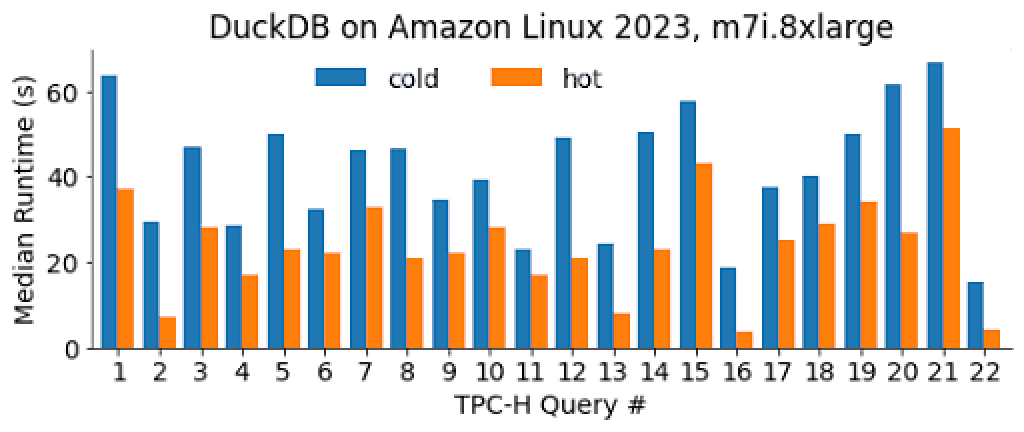
As an important reference, consider that running the 22 queries on Spark on the same single node setup took us around 800 seconds in a hot EC2. This is just a tiny bit faster than running all the 22 queries from cold EC2s with our system (!), and ~2x slower in the apple-to-apple comparison with hot runs;
Note that the test comprises the time it takes from launching the machine to receiving a snippet of the result set in the terminal. The video above illustrates a ~12 seconds cold start time for an 7i.8xlarge EC2 instance running query 13. For those of you not keeping the score, the game state so far is depicted in the chart below.
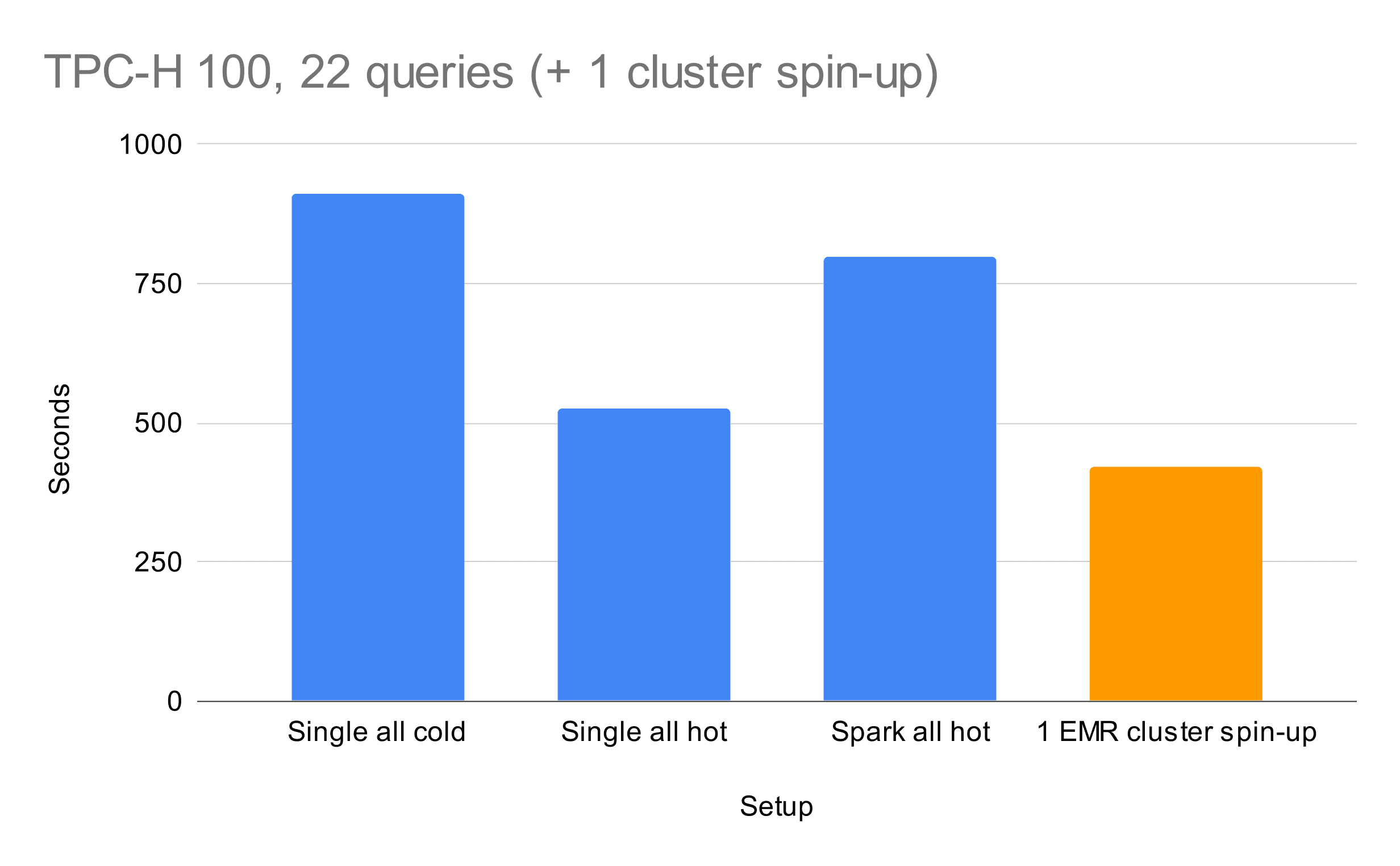
The startup time is still psychologically acceptable with a median of approximately 15s. We don’t pay any performance tax when compared to Spark, and most importantly no data ever leaves our VPC. This also means that we can leverage our cloud contracts and use our credits for these queries, with no extra bill if not your own EC2s. Finally, being “just EC2s” you can run the TCP-H 1TB just by replacing the underlying machine: the limits now are those of AWS, we are not limited by any vendor in the middle.
A note of empathy
If you work in an enterprise who has been running data workloads at scale, there is a high chance that you already have a lot of Spark code in production. This alone would be a good reason for anyone to prefer to switch to Serverless Spark, rather than rewriting all the queries with a new back-end, like we did above.
So even if we think that single-node architectures should be preferred to distributed where possible, we definitely understand that even thinking of rewriting all your Spark code makes you wanna scream in a pillow.
Since we had to face this problem first hand with literally ALL our design partners, we decided to build a Spark container to run their Spark code on a single node application. This way, we could copy and paste their code, slashing the migration costs, while still benefiting from a simpler compute model.
Conclusion
We know better than most that people use data systems, not data engines, and that the road to an end-to-end data platform production lakehouse is full of perils. That is why we think that obtaining good developer experience is one of the most important battles to fight in data.
The optimal developer experience in the cloud is one where the cloud itself becomes invisible, enabling developers to concentrate entirely on their code and their productivity. While it is true that such experience is captured by some features of the Serverless paradigm, people tend to conflate the developer experience with the underlying compute model of multi-tenant distributed cloud systems and the consequent cost structure.
These two things are not necessarily the same thing though, and we think we can achieve the former without necessarily buying into the latter.
Good data systems should strive for a serverless-like developer experience (in this case, eliminating startup times), but that does not mean that we must forcefully sacrifice the cost-efficiency, transparency and control of more traditional models.
If you are thinking about developer experience, efficiency for data workloads and you want to know more about what we do with respect to these topics, get in touch with the team at bauplan or join our private alpha.
Many thanks to Chris Riccomini, Skylar Payne, Marco Graziano and Davis Treybig for helpful comments on the first draft.
—-
[1]: Fun fact: two companies ago, we migrated our entire Spark-based “lambda architecture” to Snowflake SQL to mitigate this exact pain point. It’s open source now, so you can check it out.
[2]: In the warehouse world, this is what happened with serverless cloud warehouses like Snowflake, which provided a uniform interface for both *ad hoc* synchronous queries and batch SQL ETL jobs. The emerging design pattern is the reason for the success of frameworks like dbt, which helped going beyond querying alone in the data warehouse by providing easy ways to template pipelines.
[3]: In reality, we have no way to know whether that is the case, because the serverless offering in this specific case is an impenetrable black box for the final user.
[4]: Less than the memory of a Lambda function in 2024.
[5]: We have been talking about the reasonable scale for a while (blog series, peer-reviewed RecSys paper and popular open source reference architecture). Also other people, possibly smarter than us, agreed (big data is dead). Data from warehouse usage of real enterprise companies and published in our own VLDB 2023 paper shows that 80% of the entire warehouse spending is actually for \<1GB scans queries. In the recent Amazon 2024 VLDB paper, Redshift data show that even going to the extreme of p99.9 we arrive at “only” 250GB memory consumption per query, with 98% of tables having \<1 BN rows.
[6]: Even in those cases where multiple machines are actually needed, better systems are starting to become more popular, like Ray and Dask. We are not going to go into this here. Also, we need to put a big caveat on this for unstructured data and large amounts of streaming data ingested through Kafka or similar.




