Serverless is still not designed for data



In the last few years, the interest for serverless products has been rapidly and almost constantly growing. Serverless’s popularity is not surprising. Who wouldn’t grow tired of managing infrastructure, scaling, logging, and deployments of modular applications?
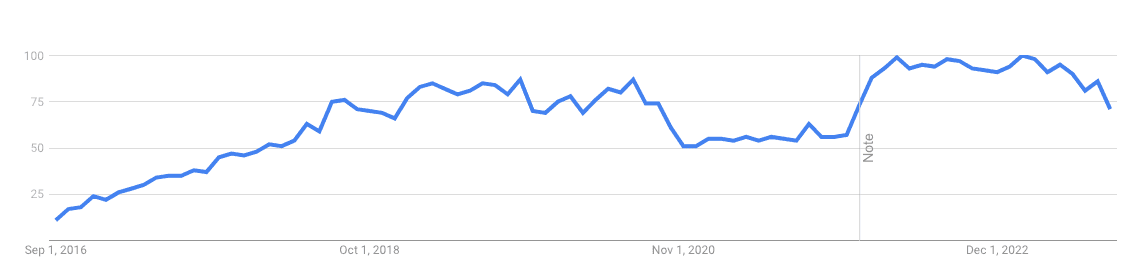
When you think about it, the more surprising fact is that serverless paradigms are not even more widespread. As some smart people argued at length, serverless is the cloud experience par excellence (1), promising a 10x productivity improvement by having you spend less / no time on infrastructure.
This promise seems not to be completely realized still. Infrastructure remains a core problem for developers around the world and even more so for data workloads, such as analytics jobs, ETL and data transformation pipelines. While data workloads are ubiquitous in the lives of developers and clearly central to the success of enterprises, most data platforms are still predominantly built on non-serverless technologies (2), such as Spark and Kubernetes clusters.
Why? Wouldn’t the ergonomics of a serverless experience be much better? Wouldn't productivity improve significantly with a more flexible and disintermediated cloud infra?
Surely, there are many good answers to these questions, starting from the obvious jack-of-all-trades explanations, inertia and pricing. However, we believe there are some very specific reasons that have to do with the functioning of data workloads and the current serverless options on the market.
Serverless wasn’t designed for moving data
“Serverless” tends to be a bit of an overloaded term nowadays, denoting many different things: scale-to-zero, price-per-second, infinite and instantaneous concurrency, stateless execution, etc. While, historically, all these features are found in the most famous implementation of serverless computing, AWS Lambda, they do not necessarily imply one another.
For a more feature-neutral point of view, we might want to keep in mind that the core concept of serverless deployment is virtualization. In an historical perspective, we went from physical hardware to first-gen IaaS (e.g. barebone EC2), from IaaS to better IaaS and PaaS (Fargate), to, finally, serverless (Lambda). At every step, the target platform takes care of one more layer, and the developer responsibility shrinks accordingly. Initially, the programmer provides everything, then it provides a VM to run on some hardware specs, then a containerized application and finally a function (3).
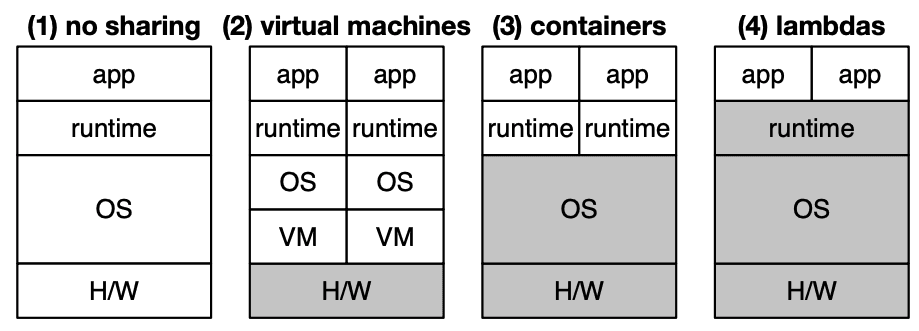
In principle, this way of thinking is particularly well suited for data workloads where functions are indeed the basic unit of abstraction that developers use in representing pipelines. The standard way to represent data pipelines is a DAG, i.e. a sequence of processes starting with data sources, whose intermediate steps output artifacts as input for subsequent steps - in the following example, the “customers” table (left) produces intermediate artifacts until the “orders” table (right) is materialized for downstream consumption (e.g. a dashboard, a ML model, a DS notebook).
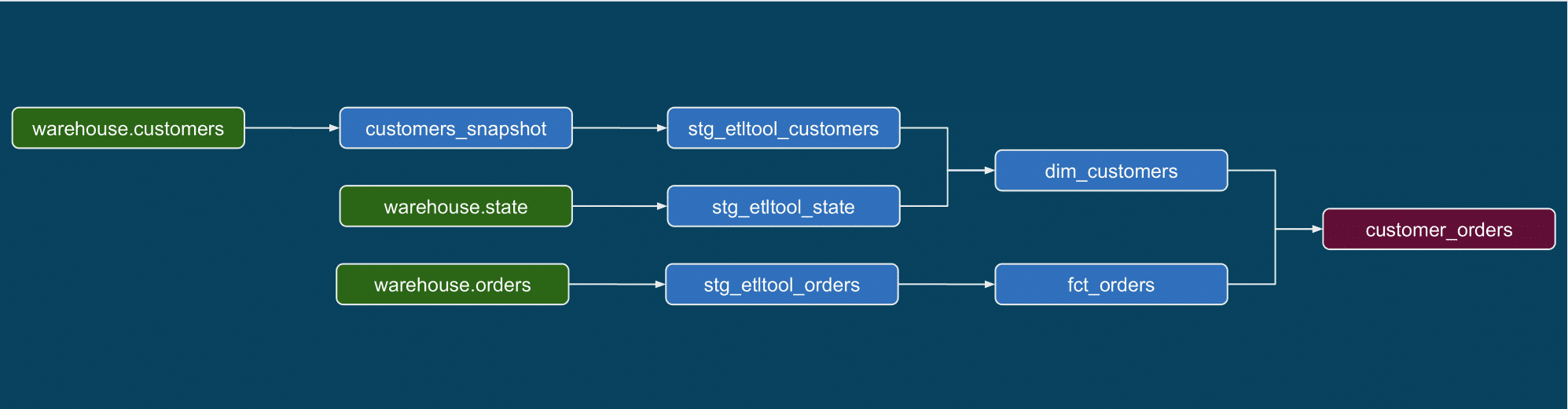
The problem for someone who would want to adopt serverless as a paradigm for data workloads is that virtually all options available on the market are not designed around this use case.
Every serverless option out there is inefficient at passing data and data locality is a problem that developers need to re-solve every time they implement serverless.
Since working with data involves many (well-grounded) privacy and security concerns, companies tend to keep data in their virtual private cloud. This in turn means that if one wanted to adopt a serverless design for data the choice is practically limited to either cloud vendors or one of the few open source projects out there (OpenWhisk, OpenFaaS, Knative). Unfortunately, neither was really designed for data. (4)

Nothing in theory prevents serverless from being applied to data pipelines, it just happens to be the case that it has been used mostly to build micro-endpoints and run glue code between cloud services. All of these use cases are focused on short-lived computation (100 ms), horizontal scaling (high concurrency, small individual throughput) and no dependencies between functions.
This is in stark contrast with data DAGs, where compute time is longer (ranging from seconds to hours), vertical scaling (nodes may need to scale up both in memory and compute power) is more important than horizontal (low concurrency, high individual throughput) and functions share something essential: data.
This last part is possibly the most important point when we need to think about serverless DAGs. To retain the benefits of functional compute, we want functions to be completely isolated as far as runtime go, with granular control on packages dependencies and even interpreter versions if needed. However, functions need also to share data artifacts, which can be bulkier than just sharing states through a common database (the difference between a table with 50 million rows and a counter). The recent academic literature just started scratching the surface on data locality within the function-as-a-service paradigm, but it is fair to say that we are still in the early days, especially when we consider that prior knowledge of data (through a catalog) and code (through static analysis) could massively improve our movement strategies in production workloads.
It’s all about moving data around
It is clear than Lambda is not suited for this task, and cannot be modified to close the gap: SQL support needs be built by developers piggy-backing on existing engine (possible but tedious, as we showed here with DuckDB); resource allocation is done at deployment time, not invocation time; finally, function isolation is absolute, and DAGs are therefore terribly slow: functions are not addressable and data passing require manual copies to durable storage, which is often required for production workloads but it is so slow that it hinders heavily production cycles.
If off-the-shelf cloud solutions won’t do the job, can an enterprise data team turn to open source frameworks, and trade-off some maintenance headaches for flexibility? After evaluating popular frameworks such as OpenWhisk, OpenFaaS and OpenLamba, there seems to be no sensible trade-off in sight. Some design choices are clearly the results of popular requirements: the frameworks can easily run a function triggered by a small payload from an HTTP call or a Kafka queue, but they have no built-in mechanism for passing artifacts around. OpenLambda functions can receive inputs through the Unix socket, but no specific API exists for data sharing (you could of course manually roll your own gRPC-like comms, but at significant implementation and maintenance cost); Redis, the recommended intermediate storage solution for OpenWhisk from Nimbella, is not suited for the type and amount of sharing we are interested in.
Other choices seem to have been influenced by general devOps trends more than serverless-specific considerations: OpenWhisk and OpenFaaS are mostly designed to run on top of K8s, inheriting its weaknesses with regard to composability and data sharing. Notably, the tried and tested solutions for scalability and redundancy that K8s provide are not as interesting for data DAGs; on the other hand, K8s adds significant deployment complexity that is not fully abstracted by the frameworks above: in our experience, running a smooth OpenWhisk platform requires indeed non-trivial understanding of the underlying infrastructure, defeating the triumph of virtualization that FaaS represents.
Of course, we are not suggesting that OpenWhisk, OpenFaaS and OpenLambda are poorly designed, or that no team should use K8s to develop complex data applications. More modestly, we are just trying to say that whatever the motivation behind the design of these frameworks was, they cannot be easily retro-fit for data-first workloads. When thinking from “first principles”, the design space is pretty large, especially since DAGs do not live in a vacuum: data lake, data catalog, table formats are all parts of an effective implementation of “data pipelines”. If, as Wes McKinney recently argued, the vectorization stack is getting commoditized through open source, composing the other pieces within the right abstractions is more important than ever for differentiation.
We discussed some of the design choices we made when building Bauplan in our VLDB paper. In Part Two, we will dive deeper into industry-wide constraints on data lakehouse, and discuss available options from a different point of view: developer experience.
Stay tuned and join our mailing list to know more (we won’t spam you!).
We wish to thank Ethan Rosenthal, Simon Gelinas and Ryan Vilim for precious feedback on a previous draft.
Footnotes
- In fact, we bought into the concept pretty early. A long time ago, in a seed round far far away, we were already building auto-scalable analytics platforms and cheap Tensorflow serving with AWS Lambdas and a bit of ingenuity.
- Lately a number of products have been labeled as serverless, such as AWS glue, Serverless EMR. This is a good sign that things are moving towards serverless even for data.
- Thanks to our academic friends at the University of Wisconsin Madison, who spent the past five years working on FaaS and made it so easy to understand.
- A new breed of providers started to build more modern serverless services. We are talking about a handful of extremely interesting startups, like ModalLabs, FAL.ai, and Banana Dev who double clicked on the idea that containerization should be taken care of inside the serverless platform itself, freeing developers from the burden of a slow feedback loop. They are currently all focused on GPU inference, which makes perfect sense given that GPUs are expensive for small companies doing AI experime
- nts, and hence particularly suited for pay-per-second multi-tenant options. It is early to say where these companies will go, but we believe they are onto something.




