


We believe your data infrastructure should be cost-effective, future proof and invisible.
We make it happen in a few lines of code.
Self-optimizing serverless runtime

bauplan runs data workflows as ephemeral functions that spin up instantly and disappear when done.
Resources are optimized automatically, maximizing efficiency with zero overhead.
Let engineers build, not manage infrastructure.
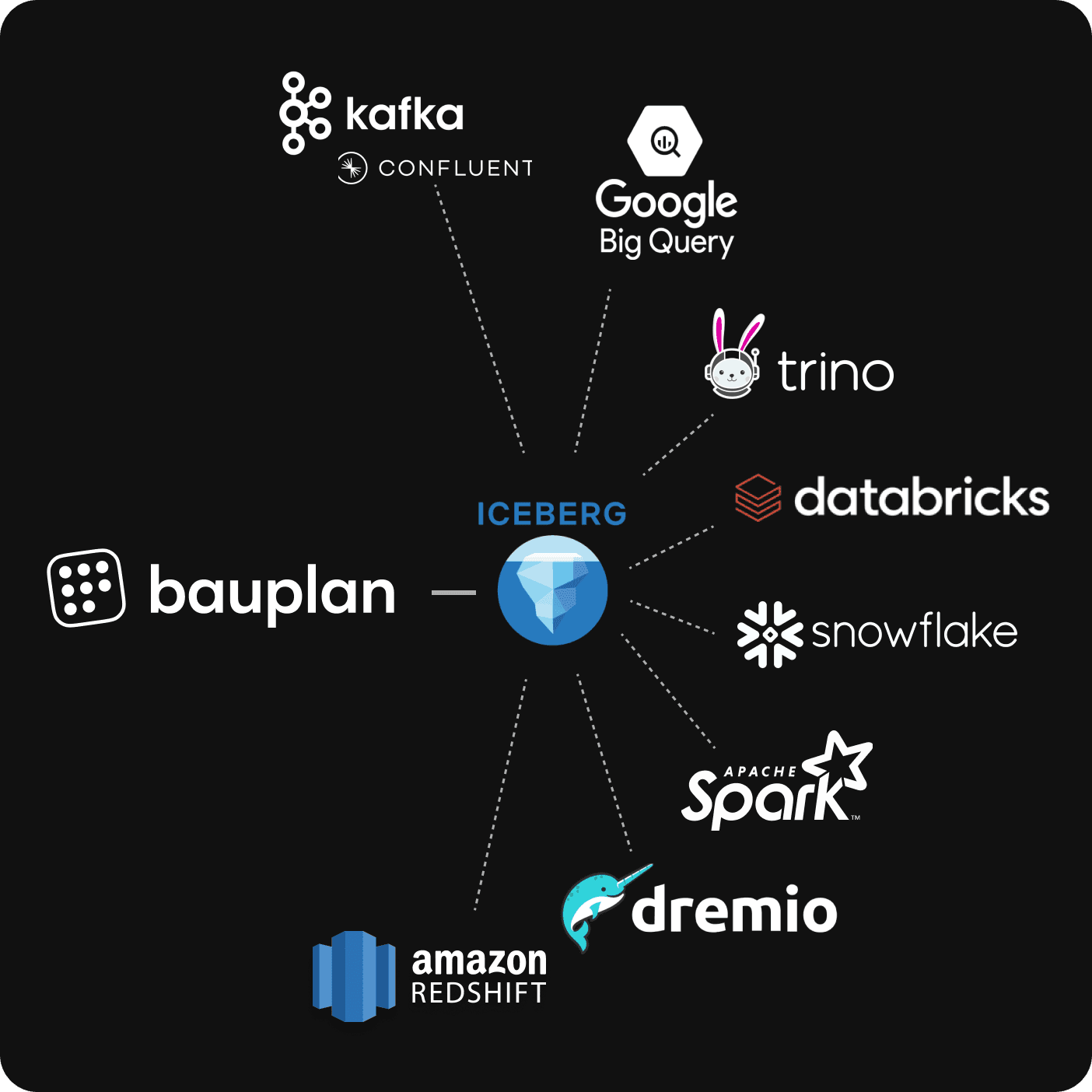
Open Lakehouse Architecture
Native Apache Iceberg support in your object storage means you can easily integrate with your preferred tools and switch platforms whenever you need.
Never feel trapped by your data infrastructure again.
In code: everything happens from the code

No infrastructure, it feels like local!
Start functions in milliseconds with no setup. Define dependencies in code while we handle data movement and infrastructure, ensuring end-to-end compatibility.
Test and develop safely with zero-copy data branches
Create isolated development environments and work with full-size production data copies without storage costs or risking production workflows.


Automate everything with Python
Integrate your data platform's full capabilities directly into your applications, tools, and CI/CD pipeline using our SDK.
